 Star on GitHub
Star on GitHub
Dev Tools for API Testing: What to Standardize Across Teams
API testing falls apart at scale for predictable reasons: every team invents its own folder layout, environment variable names, chaining conventions, assertion style, and CI reporting. The result is not “more tests”, it is more entropy. You get brittle flows, noisy diffs, and PRs nobody can confidently review.
Standardization is the fix, but not in the “everyone writes identical tests” sense. What you want is a shared contract for how tests are expressed, reviewed, and executed so any engineer can open a PR, understand the intent, and trust the CI signal.
DevTools fits well here because it keeps API tests as native YAML (not a UI-locked format or a custom DSL), which makes standards enforceable via Git workflows, CODEOWNERS, linters, and normal code review. This article focuses on what to standardize across teams when your API tests are YAML-first and CI-native.
What “standardize” should mean (and what it should not)
Standardization should define:
- Interfaces: file layout, naming, env variables, how chaining works, how assertions are written.
- Determinism rules: what is forbidden (volatile headers, wall-clock assertions as merge gates, shared state).
- CI contract: exit codes, report formats, artifact paths, and what gets uploaded.
Standardization should not define:
- Exact endpoints or payloads.
- The one true test suite structure for every service.
- “Framework magic” that hides request dependencies.
If you are migrating from Postman/Newman or Bruno, this is the core difference: instead of standardizing how people click around a GUI (or a tool-specific export format), you standardize a Git-reviewed YAML representation that CI runs exactly the same way every time.
Standardize the repo layout (so suites compose cleanly)
Pick a layout that works for monorepos and polyrepos, supports sharding, and makes it obvious what is safe to commit.
A pragmatic baseline:
api-tests/
flows/
smoke/
regression/
env/
local.env
ci.env
staging.env
prod.env
env.example
fixtures/
requests/
responses/
scripts/
redact-har.sh
seed-test-data.sh
.gitignore
Key decisions to standardize:
- Flow file granularity: prefer many small flows over a few giant suites. This makes CI sharding deterministic and reduces merge conflicts.
- Smoke vs regression definition: “smoke” should be fast and safe to run on every PR. “regression” is broader and may run on merge, nightly, or by label.
- HAR hygiene: if you generate flows from browser traffic, standardize that raw
.harfiles are not committed (commit the sanitized YAML). DevTools already leans into this workflow via HAR to YAML conversion.
If you want the CI implications and parallelization mechanics, DevTools has a deeper guide on pipeline-native execution in API Testing in CI/CD.
Standardize the environment variable contract (names, scoping, and overrides)
Most “tool migrations” fail because each team invents different variable names and secret handling. Standardize the environment contract once, and treat it like an API.
Required variables: define a stable minimum
A common baseline that scales:
BASE_URLAUTH_TOKEN(optional, if your flows obtain tokens via login chaining, do not require this)CLIENT_ID,CLIENT_SECRET(if using OAuth client credentials)TENANT_ID(if multi-tenant)CI_RUN_ID(for uniqueness)
Create an env.example that documents required keys and expected formats, and make CI fail fast if they are missing.
Secrets policy: never commit, never bake into YAML
Standardize:
- Secrets come from CI secret stores (GitHub Actions Secrets, Vault, cloud secret managers).
- YAML references secrets only via env var interpolation.
- Recorded traffic must be sanitized (cookies, authorization headers, PII). If you are doing HAR capture, align on a redaction checklist. DevTools has a dedicated guide for this: How to Redact HAR Files Safely.
Base URL policy: no hardcoded hostnames
Hardcoded URLs are the fastest way to end up with “works on my staging” tests.
A minimal pattern:
# flows/smoke/health.yaml
steps:
- id: health
request:
method: GET
url: ${BASE_URL}/health
assert:
status: 200
Even if your runner supports defaults, standardize explicitness. It keeps flows portable across repos and execution contexts.
Standardize step naming (because reporting depends on it)
Your CI report is only as useful as the names it emits.
Standardize a naming scheme that is:
- Stable over time
- Unique across the repo
- Mappable to ownership boundaries
A simple convention:
- Flow path indicates suite (smoke vs regression)
- Step
idindicates intent (not just endpoint)
Example:
# flows/regression/billing/invoice-lifecycle.yaml
steps:
- id: auth.login
- id: invoice.create
- id: invoice.get
- id: invoice.void
- id: invoice.verify_voided
This pays off when emitting JUnit (or similar) because your failures show up as meaningful test cases instead of “Request 7 failed”. If you want a detailed, CI-focused treatment, see JUnit Reports for API Tests.
Standardize request chaining (make dependencies explicit)
Chaining is where teams most often drift into hidden state and flakiness. Standardize the “data flow rules” so reviewers can reason about the sequence.
Rule: extract once, reference everywhere
Prefer a single extraction point for IDs/tokens, and reference that variable downstream.
Representative pattern:
steps:
- id: auth.login
request:
method: POST
url: ${BASE_URL}/api/login
headers:
content-type: application/json
body:
username: ${USERNAME}
password: ${PASSWORD}
extract:
access_token: $.accessToken
assert:
status: 200
- id: invoice.create
depends_on: [auth.login]
request:
method: POST
url: ${BASE_URL}/api/invoices
headers:
authorization: Bearer ${access_token}
content-type: application/json
body:
externalRef: ${CI_RUN_ID}
amountCents: 499
extract:
invoice_id: $.id
assert:
status: 201
- id: invoice.get
depends_on: [invoice.create]
request:
method: GET
url: ${BASE_URL}/api/invoices/${invoice_id}
headers:
authorization: Bearer ${access_token}
assert:
status: 200
json:
- path: $.id
equals: ${invoice_id}
Standardization points:
- Dependency declaration (
depends_onor equivalent) is required when one step consumes another step’s outputs. - No reliance on cookie jars or implicit session state unless the flow explicitly asserts it.
- Correlation for uniqueness: mandate a per-run identifier (
CI_RUN_ID) used in create operations to avoid collisions in parallel CI.
DevTools already leans into chaining patterns and multi-step flows. If you want deeper workflow patterns (polling, branching, loops), see API Workflow Automation: Testing Multi-Step Business Logic.
Standardize assertion strategy (invariants first, snapshots selectively)
Teams tend to either under-assert (“status 200”) or over-assert (full payload snapshots that flake). Standardize what “good” looks like.
A workable policy for most API suites:
| Assertion type | Standardize when to use | What to avoid |
|---|---|---|
| Status + key headers | Every request | Ignoring caching / content-type regressions |
| JSON invariants (JSONPath) | Default for response bodies | Exact matching of volatile fields (timestamps, IDs you did not create) |
| Schema/contract checks | Broad coverage, especially for public APIs | Treating schema as a substitute for workflow correctness |
| Snapshots (golden responses) | Only for complex nested payloads that are hard to assert | Raw snapshots without canonicalization/redaction |
For error responses, standardize a contract. If you use RFC 7807 problem details, assert the structure and stable fields (type, title, status), see RFC 7807.
If your teams are debating schema vs snapshots, DevTools has a CI-grounded discussion here: Schema vs Snapshot Testing for APIs.
Standardize determinism guardrails (what reviewers must block)
This is the part that separates a test suite from a CI liability.
Volatile request data
Standardize a denylist for headers and fields that should not appear unless justified:
User-Agent,sec-*,accept-language(browser noise)- Dynamic tracing headers that change every request (unless you intentionally assert propagation)
- Cookies captured from a browser session (replace with explicit auth chaining)
Time and polling
Standardize:
- Polling loops must have bounded attempts and a clear timeout.
- Timing assertions are budgets, not hard gates, unless you have stable performance environments.
Retries
Retries should be scoped. Standardize that retries are allowed for:
- Network timeouts
- 429 rate limits (with backoff)
Retries should not mask deterministic failures (400, 401, 403, assertion failures).
If you want a CI-specific playbook for secrets/auth/retries/rate limits, see API Testing in GitHub Actions: Secrets, Auth, Retries, Rate Limits.
Standardize parallel safety (data isolation and cleanup)
Once you run tests in parallel (or multithreaded locally), shared mutable state becomes your biggest flake source.
Standardize the following rules:
- Each flow owns its data: create unique resources, assert, then cleanup.
- Unique naming: prefix created entities with
${CI_RUN_ID}(or a generated suffix) so parallel jobs do not collide. - Idempotency where possible: use idempotency keys for create endpoints that support them.
- Teardown is non-optional for suites that run on shared environments.
A practical cleanup pattern:
steps:
- id: widget.create
# ...extract widget_id...
- id: widget.delete
depends_on: [widget.create]
request:
method: DELETE
url: ${BASE_URL}/api/widgets/${widget_id}
headers:
authorization: Bearer ${access_token}
assert:
status: 204
For more on making multi-request sequences deterministic, see API Chain Testing.
Standardize CI output (reports, artifacts, exit codes)
If different repos emit different artifacts, platform teams cannot build reliable dashboards, and engineers cannot debug failures quickly.
Define a single contract for every CI run:
- Always emit JUnit XML to a known path.
- Always emit machine-readable JSON (optional, but helpful for custom tooling).
- Always upload runner logs as artifacts on failure.
- Always exit non-zero on assertion failures.
A simple “commit vs artifact” standard helps prevent repo bloat and security leaks:
| Item | Store where | Why |
|---|---|---|
| YAML flows | Git | Reviewable, diffable source of truth |
env templates (env.example) | Git | Onboarding and determinism |
| Raw HAR | Not in Git | High risk for secrets/PII, noisy |
| JUnit XML | CI artifact | Debuggable failures, PR annotations |
| Full logs | CI artifact | Post-mortems without reruns |
If you are standardizing on GitHub Actions, also standardize version pinning (runner images, actions, CLIs) to avoid silent breakage. See Pinning GitHub Actions + Tool Versions.
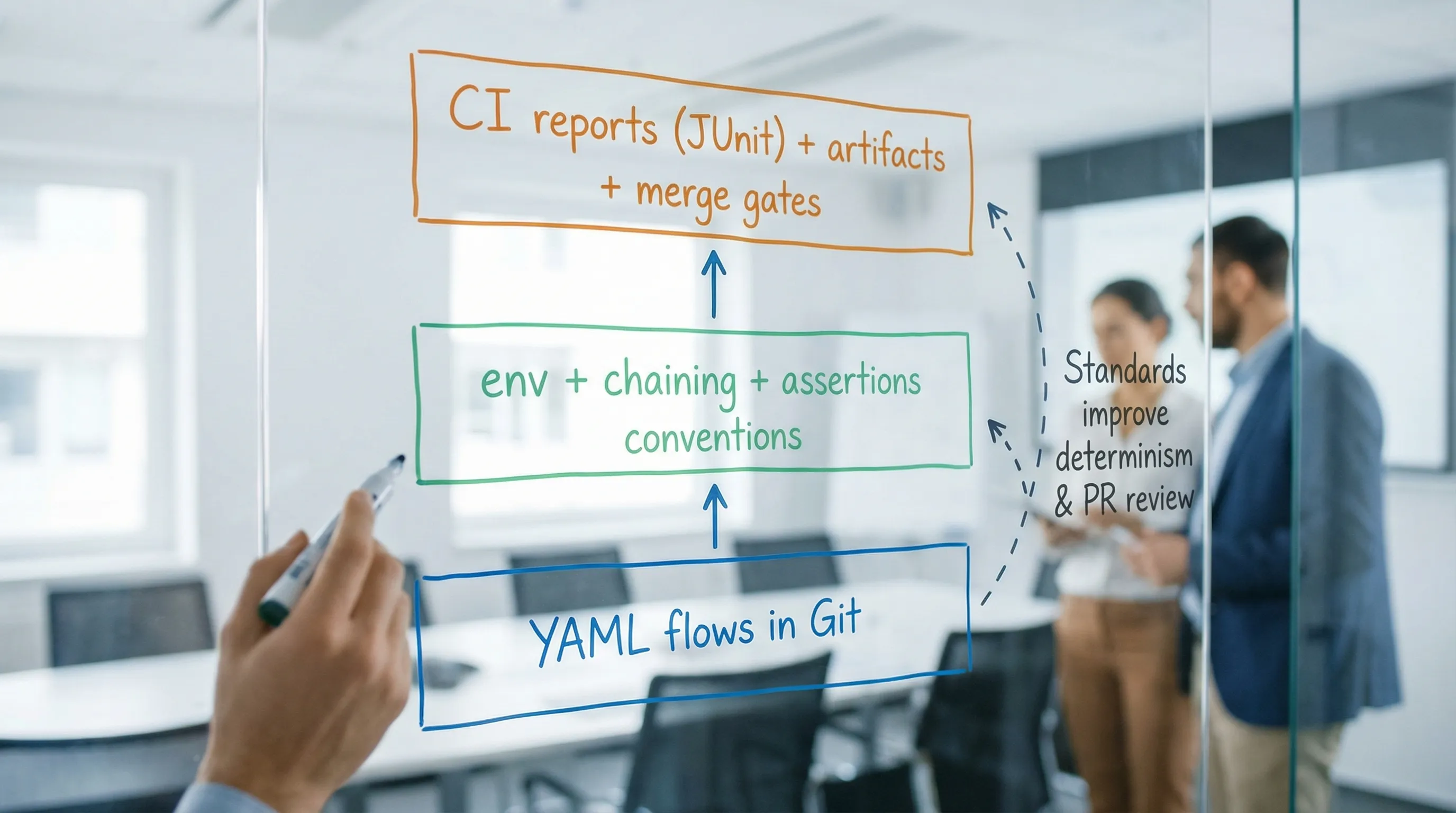
Standardize governance (ownership, review gates, and enforcement)
Standards that live in a wiki die. Standards that are enforced in Git survive.
Practical governance that experienced teams use:
- CODEOWNERS for suites: route changes in
flows/regression/billing/to the billing team. - PR template checklist: “no secrets, no hardcoded base URLs, explicit dependencies, deterministic assertions, cleanup.”
- Pre-commit hooks: reject committed
.har, run YAML formatting checks, block accidental secret patterns. - CI lint job: fail on missing required env keys, unpinned versions, or disallowed headers.
If you want a review-focused checklist that aligns with YAML-first testing, DevTools has a dedicated guide: Codes Review Checklist for YAML API Tests (No UI Required).
Tooling reality check: Postman/Newman, Bruno, and native YAML
Standardization is easier when your test format is stable, reviewable, and not mediated by a UI.
Postman + Newman
- Collections are fundamentally a tool-owned format. You can export JSON, but it is not optimized for human diffs.
- Teams often end up with “CI scripts” that depend on Postman-specific behaviors, plus brittle pre-request scripting.
- Review is hard: diffs are noisy, ordering changes happen, and intent is buried.
Bruno
- Bruno is file-based and Git-friendlier than many GUI tools.
- But it still introduces a tool-specific representation and conventions you must standardize around.
DevTools (YAML-first)
- Native YAML keeps tests readable and portable across teams.
- Chaining and determinism conventions can be encoded as code review norms and CI checks.
- HAR to YAML workflows give you a realistic starting point, then your standards shape the output into maintainable flows.
If your organization is actively replacing Newman, the DevTools-specific migration path is covered in Newman alternative for CI: DevTools CLI.
A practical “team standard” you can actually adopt
If you want this to stick, write a short standard (1 to 2 pages) and enforce it in CI. Keep it concrete:
- Repo layout: where flows, env, fixtures live
- Env contract: required variables and naming
- Chaining rules: explicit dependencies, extract once
- Assertions policy: invariants first, snapshots selectively
- Determinism guardrails: banned headers, bounded polling, scoped retries
- Parallel safety: unique IDs, cleanup required
- CI contract: JUnit path, artifact retention, exit codes
- Governance: CODEOWNERS, PR checklist, lint rules
That is the difference between “we have API tests” and “we have an API test system” that multiple teams can evolve without breaking each other.