 Star on GitHub
Star on GitHub
Codes Review Checklist for YAML API Tests (No UI Required)
If your API tests live in a UI, your “review” is mostly trust. A teammate says they updated a Postman collection, CI runs Newman, and you get a green check. The problem is that the test logic, chaining, and assertions are not first-class code artifacts, so reviewers cannot reliably answer the questions that matter: what changed, why it changed, and whether it will be deterministic in CI.
YAML-first API tests flip that. When flows are native YAML in Git, the pull request diff is the source of truth. This article is a practical codes review checklist (code review checklist) for YAML API tests that assumes experienced reviewers and CI-native workflows.
What “reviewable” means for YAML API tests
A reviewable YAML API test has three properties:
- Diffable: the meaningful behavior change is visible in a Git diff (not hidden behind UI state or re-serialized exports).
- Deterministic: it passes or fails for product reasons, not because timestamps moved, ordering changed, or the environment drifted.
- Composable: request chaining is explicit, so the flow documents dependencies and can be re-run locally and in CI.
This is where YAML-native tooling differs from common alternatives:
- Postman + Newman: collections are JSON exports with a lot of incidental structure, plus test logic often lives in scripts. PR diffs tend to be noisy, and “reviewing” often means importing into Postman to understand intent.
- Bruno: tests are stored as files, which is good, but the format is a custom DSL (
.bru), so you still have a tool-specific representation to learn and standardize. - Native YAML flows: reviewers can read requests, variables, and assertions directly in the PR, and apply the same engineering standards as any other code.
If you are already using DevTools flows, the companion pieces worth keeping open while reviewing are:
- Git-Friendly YAML API Tests: Formatting Rules That Keep Diffs Clean
- Deterministic API Assertions: Stop Flaky JSON Tests in CI
- API Testing in GitHub Actions: Secrets, Auth, Retries, Rate Limits
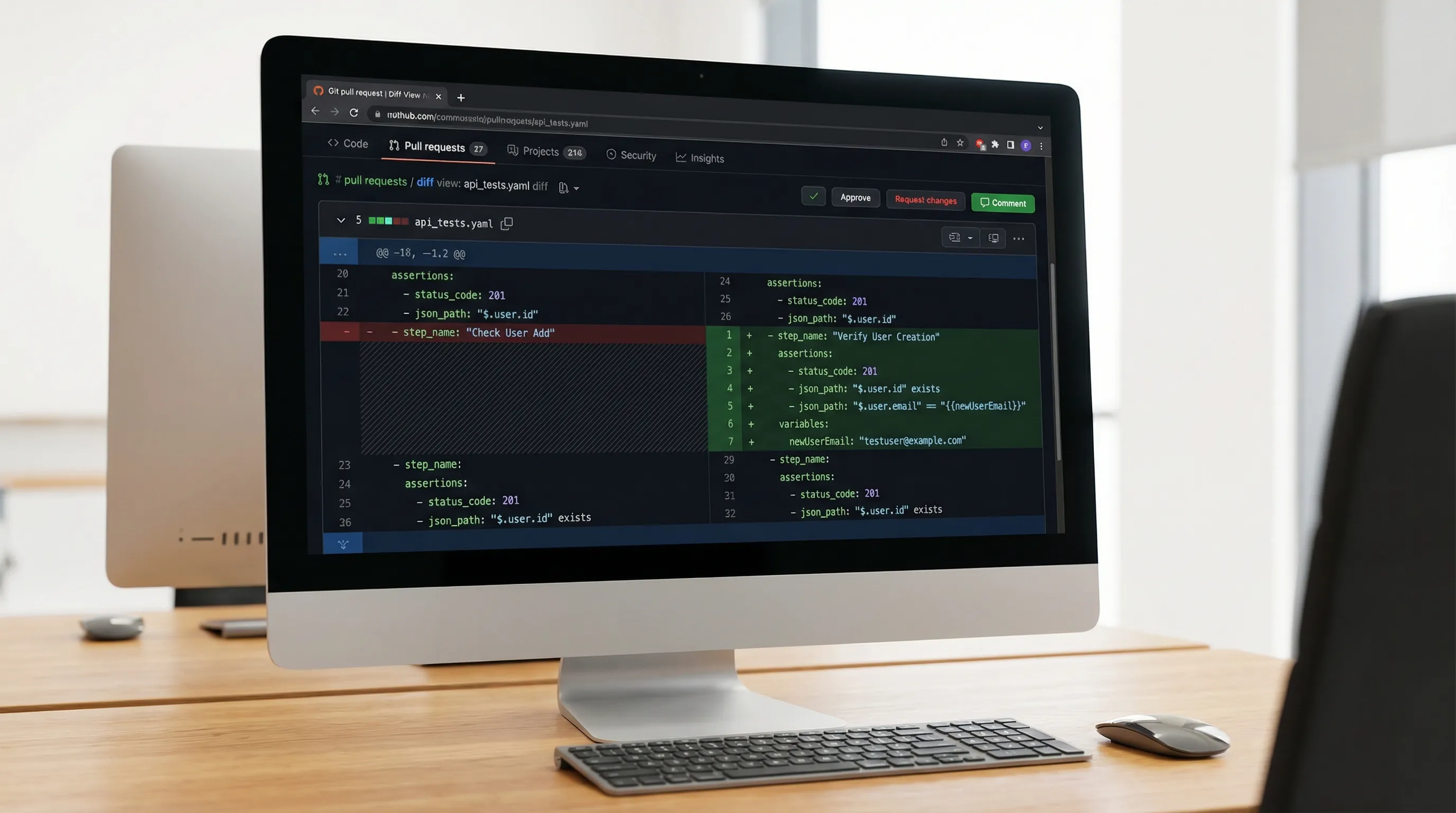
The PR checklist (what to verify, and why)
Use the table below as the baseline reviewer checklist. It is intentionally biased toward catching CI flakes, bad chaining, and non-reviewable diffs.
| Review area | What to look for in the diff | Why it matters in CI and Git |
|---|---|---|
| Secrets and auth | No tokens, cookies, API keys, session IDs, or PII committed. New auth mechanisms use env vars or CI secrets, not copied headers. | Prevents leaks and “works on my machine” sessions. Keeps flows shareable. |
| Base URLs and environment | URLs are parameterized (per env) instead of hardcoded to a dev machine, preview URL, or a one-off tenant. | Makes the same flow runnable locally, in PR checks, and in nightly runs. |
| Volatile headers | Removed or normalized headers like User-Agent, Sec-*, dynamic tracing headers, random request IDs, and anything browser-noisy. | HAR-derived tests often fail due to irrelevant browser headers. |
| Request chaining | IDs, tokens, CSRF values, cursors, and Location headers are captured once and referenced later. No “magic” values in later steps. | Eliminates hidden coupling to pre-existing state. Improves debuggability. |
| Assertions | Assertions validate invariants (types, presence, allowed values), not brittle full-body snapshots unless normalized. | Prevents flakes from timestamps, ordering, and irrelevant fields. |
| Data isolation | Flow creates its own resources (unique run ID), does not rely on global fixtures unless explicitly managed. | Enables parallel runs and reduces cross-test interference. |
| Cleanup | Created resources are deleted (or a teardown flow exists). For non-idempotent systems, the cleanup strategy is explicit. | Keeps environments from accumulating state and breaking later tests. |
| Timing and retries | No unconditional sleeps. Polling/retry is scoped to eventual consistency points, with bounds and backoff. | Avoids slow, flaky pipelines and hidden timeouts. |
| Naming and structure | Step names are stable and descriptive. Changes do not reorder large blocks without reason. | Makes diffs reviewable and maps cleanly to CI reports. |
| CI compatibility | Flow can run headless without UI state. CI steps pin tool versions, emit JUnit/JSON, and preserve minimal artifacts for debugging. | Makes failures diagnosable and protects against tool drift. |
1) Secrets and sessions: “If it came from a browser, assume it is toxic”
Most review failures in YAML API tests come from accidentally committing replayable sessions.
During review, search the diff for:
Authorization: Bearer ...literalsCookie:literalsX-CSRF-Tokenvalues- JWT-looking strings (
eyJ...) - Email addresses, phone numbers, tenant IDs
If the YAML was generated from HAR, enforce this policy:
- Raw
.harfiles are not committed. - YAML flows are committed only after redaction and parameterization.
Reference: How to Redact HAR Files Safely (Keep Tests Shareable, Remove Secrets).
A reviewer-friendly pattern is “declare secrets as environment variables, chain everything else”. For example (illustrative YAML pattern):
env:
BASE_URL: ${BASE_URL}
API_TOKEN: ${API_TOKEN}
steps:
- name: whoami
request:
method: GET
url: ${BASE_URL}/v1/me
headers:
Authorization: Bearer ${API_TOKEN}
assert:
status: 200
jsonpath:
"$.id":
exists: true
Review question to ask: Does this flow still work if I rotate credentials and run it in a clean environment? If the answer is “no”, it is not ready.
2) Request chaining: make dependencies explicit, or expect flakes
Chaining is where YAML tests either become reliable workflow checks or degrade into “copy/paste a bunch of requests”. The review goal is to ensure each step’s inputs come from:
- environment variables (for configuration)
- extracted values from prior responses (for runtime correlation)
- deterministic literals (for constants)
A practical chain example (illustrative YAML pattern):
steps:
- name: login
request:
method: POST
url: ${BASE_URL}/auth/login
headers:
Content-Type: application/json
body:
email: ${TEST_USER_EMAIL}
password: ${TEST_USER_PASSWORD}
extract:
access_token: "$.accessToken"
assert:
status: 200
jsonpath:
"$.accessToken":
type: string
- name: create_project
request:
method: POST
url: ${BASE_URL}/v1/projects
headers:
Authorization: Bearer ${access_token}
Content-Type: application/json
body:
name: "ci-${RUN_ID}"
extract:
project_id: "$.id"
assert:
status: 201
jsonpath:
"$.id":
type: string
- name: get_project
request:
method: GET
url: ${BASE_URL}/v1/projects/${project_id}
headers:
Authorization: Bearer ${access_token}
assert:
status: 200
jsonpath:
"$.name":
equals: "ci-${RUN_ID}"
Reviewer checks that catch real bugs:
- No hidden coupling: if
project_idappears as a literal anywhere, send it back. - Chaining happens immediately: capture the ID in the response that produced it (not three steps later).
- Headers are not copy/pasted blindly: later requests should carry only what they need.
If your org still relies on Postman scripts for this, you can often eliminate most scripting by making correlation explicit in YAML, which is easier to review and harder to accidentally break.
For deeper chaining and multi-step business logic patterns, keep this handy: API Workflow Automation: Testing Multi-Step Business Logic.
3) Assertions: prefer invariants over snapshots (unless you normalize)
Reviewers should treat assertions as the contract of the flow. The anti-pattern is “status 200 everywhere” plus an occasional brittle full-body comparison.
A good assertion set usually contains:
- status: including expected non-200s for negative cases
- headers: content type, cache policy where relevant, location headers on creates
- body invariants: existence, type checks, enum membership, numeric bounds
Illustrative YAML assertion pattern:
- name: list_projects
request:
method: GET
url: ${BASE_URL}/v1/projects?limit=50
headers:
Authorization: Bearer ${access_token}
assert:
status: 200
headers:
Content-Type:
contains: "application/json"
jsonpath:
"$.items":
type: array
"$.items[0].id":
exists: true
Review guidance for “snapshot-like” expectations:
- If the diff adds a snapshot, require evidence it is canonicalized (timestamps removed, ordering normalized, IDs redacted) or it will flake.
- If a field is inherently unstable (timestamps, UUIDs, ETags, request IDs), assert format/type, not equality.
References:
- JSON Assertion Patterns for API Tests: A Practical Guide (with YAML Examples)
- Schema vs Snapshot Testing for APIs: What Actually Works in CI
4) Data isolation and cleanup: design for parallel runs
If your pipeline shards flows or runs them concurrently, reviewers must reject any test that assumes shared mutable state.
The simplest review rule is:
- Every flow that creates data must either delete it, or namespace it under a unique
RUN_ID.
Illustrative cleanup pattern:
steps:
- name: delete_project
request:
method: DELETE
url: ${BASE_URL}/v1/projects/${project_id}
headers:
Authorization: Bearer ${access_token}
assert:
status:
any_of: [200, 204]
If deletion is not reliable (event-driven cleanup, soft deletes, async), the reviewer should insist on one of:
- a bounded polling step that waits until the resource disappears
- a separate teardown flow that runs even on failure (CI responsibility)
Also watch for “test-only fixtures” that are shared across runs. Those are fine if they are immutable and clearly marked as such. Otherwise, they create order dependence.
5) Timing, retries, and eventual consistency: no unconditional sleeps
If a diff introduces sleep: 5000 (or equivalent), it is usually a smell.
What to accept instead:
- retries scoped to specific transient statuses (for example 409/429/503)
- polling loops that terminate with a hard timeout
- idempotency keys on retried creates
During review, ask:
- What failure mode is this retry masking?
- Is the operation idempotent? If not, how do we prevent duplicate writes?
- Are we respecting rate limits? If a flow runs in 10 shards, “just retry” can become a thundering herd.
This is a CI plumbing issue as much as a test issue, see: API Testing in GitHub Actions: Secrets, Auth, Retries, Rate Limits.
6) YAML hygiene: optimize diffs for humans, not serializers
A large percentage of “bad reviews” happen because the diff is unreadable.
Reviewers should enforce:
- stable key ordering
- sorted headers and query params
- consistent quoting for ambiguous scalars
- block scalars for large JSON bodies (to avoid single-line noise)
- stable step naming (renames are meaningful, not cosmetic)
If a PR contains massive reorder-only diffs, send it back and ask for:
- formatting changes isolated in their own commit, or
- a pre-commit formatter so the team stops fighting the same battle
Reference: YAML API Test File Structure: Conventions for Readable Git Diffs.
7) CI review points: pin versions, emit artifacts, keep failures actionable
Even with perfect YAML, CI can rot. Reviewers should check the workflow changes (if any) with the same seriousness as test changes.
Key items to verify in CI YAML:
- Pinned tool versions (runner image, actions, the test runner CLI)
- JUnit output published so failures show up in the PR UI
- Artifacts uploaded (logs, minimal results), but not raw secrets or full unredacted payload dumps
A minimal example of “pin and report” (illustrative GitHub Actions snippet):
- name: Run API flows
run: |
./devtools run ./flows --report-junit ./artifacts/junit.xml --report-json ./artifacts/results.json
- name: Upload artifacts
uses: actions/upload-artifact@<pinned-commit-sha>
with:
name: api-test-artifacts
path: artifacts/
For more complete CI patterns (parallel shards, caching, PR reporting), see:
- API regression testing in GitHub Actions
- Pinning GitHub Actions + Tool Versions: Stop CI Breakage (DevTools Included)
- JUnit Reports for API Tests: Make GitHub Actions Show Failures Cleanly
Review heuristics by change type
New flow added
Look for correctness and maintainability:
- flow starts from a clean, reproducible auth step (or uses a documented token source)
- every step asserts something meaningful
- chain values are extracted and reused, no copied IDs
- cleanup exists, or there is a documented reason it cannot
Existing flow modified
Look for “intent alignment”:
- assertion changes are explained by an API contract change, not by “make CI green”
- removed assertions have a justification
- request changes do not introduce browser-only noise
Refactor only
Look for safety:
- no behavior change hidden in formatting
- step renames preserve stable reporting identifiers (important for JUnit history)
- reordered blocks are justified (or avoided)
Red flags that should block a merge
- committed secrets or replayable sessions
- hard-coded environment-specific URLs
- sleeps added instead of bounded polling
- snapshot assertions added without normalization
- “status 200 only” checks for business-critical steps
- shared global resources without namespacing or cleanup
Frequently Asked Questions
What should I review first in a YAML API test PR? Start with secrets and determinism: verify no committed tokens/cookies, no hard-coded env URLs, and no brittle snapshot assertions.
How is YAML test review different from Postman/Newman review? With YAML in Git, you can review requests, chaining, and assertions directly in the PR diff. Postman collections often require importing into a UI to understand behavior.
What is the biggest cause of flaky YAML API tests in CI? Hidden coupling to state (hard-coded IDs, shared fixtures) and unstable assertions (timestamps, ordering, non-canonical snapshots). Second is auth drift (expired sessions copied from browsers).
Should we allow snapshot testing in YAML flows? Yes, but only for payloads that are canonicalized and redacted. Otherwise snapshots tend to fail on harmless changes.
How do I keep request chaining readable as flows grow? Extract values as close as possible to where they are produced, reference them immediately, and keep step names stable and specific.
What should we store as CI artifacts for API test runs? Store JUnit XML and minimal logs/results for debugging. Avoid raw HARs and full unredacted request/response dumps unless you have a redaction policy.
Put the checklist into practice with Git-native YAML flows
If your team is trying to get out of UI-locked test definitions (or make Postman/Newman runs actually reviewable), the fastest path is to standardize on native YAML flows in Git and enforce the checklist above in PRs.
DevTools is built around that workflow: record real traffic, export human-readable YAML, review it in pull requests, and run it locally or in CI. Start with the CI setup guide, then tighten your review standards:
- API regression testing in GitHub Actions
- Git Workflow for YAML API Tests: PR Checks, Reports, Merge Rules
Get the tool and keep your tests local-first and Git-first: https://dev.tools