 Star on GitHub
Star on GitHub
YAML API Test File Structure: Conventions for Readable Git Diffs
Readable API tests are not just about “human friendly syntax”. They are about predictable Git diffs, reviewable changes, and deterministic CI runs.
When a YAML API test file is treated as an interface (not an output artifact), structure and conventions matter as much as the assertions themselves. This article proposes a set of conventions that keep your YAML stable under change, make request chaining obvious, and minimize diff noise in pull requests.
What “good structure” optimizes for
Experienced teams usually converge on the same goals:
- Diff stability: small changes produce small diffs.
- Determinism: tests behave the same locally and in CI.
- Traceability: reviewers can map a test change to a product/API change.
- Composable request chaining: data captured from one response is reused intentionally, with minimal hidden state.
- Tool portability: files remain useful even if you change runners.
YAML helps because it is readable and can be formatted consistently, but YAML alone does not guarantee clean diffs. That comes from conventions.
Recommended repo layout (so diffs stay local)
A common source of noisy diffs is mixing environments, secrets, and flows in the same files. Keep concerns separated.
| Path | Purpose | Git guidance |
|---|---|---|
flows/ | Executable flows (API tests, workflows) | Commit |
flows/_lib/ | Reusable snippets, shared headers, common assertions (if your runner supports includes) | Commit |
env/ | Non-secret environment definitions (base URLs, feature flags) | Commit |
env/.local/ | Developer overrides | Ignore |
secrets/ or CI secret store | Tokens, passwords, private keys | Do not commit |
fixtures/ | Request/response payload fixtures | Commit |
scripts/ | CI wrappers, helpers | Commit |
Even if your runner does not support includes, keeping payload fixtures out of the flow YAML reduces churn. A one-line reference changing is a cleaner diff than reflowing a 200-line JSON body.
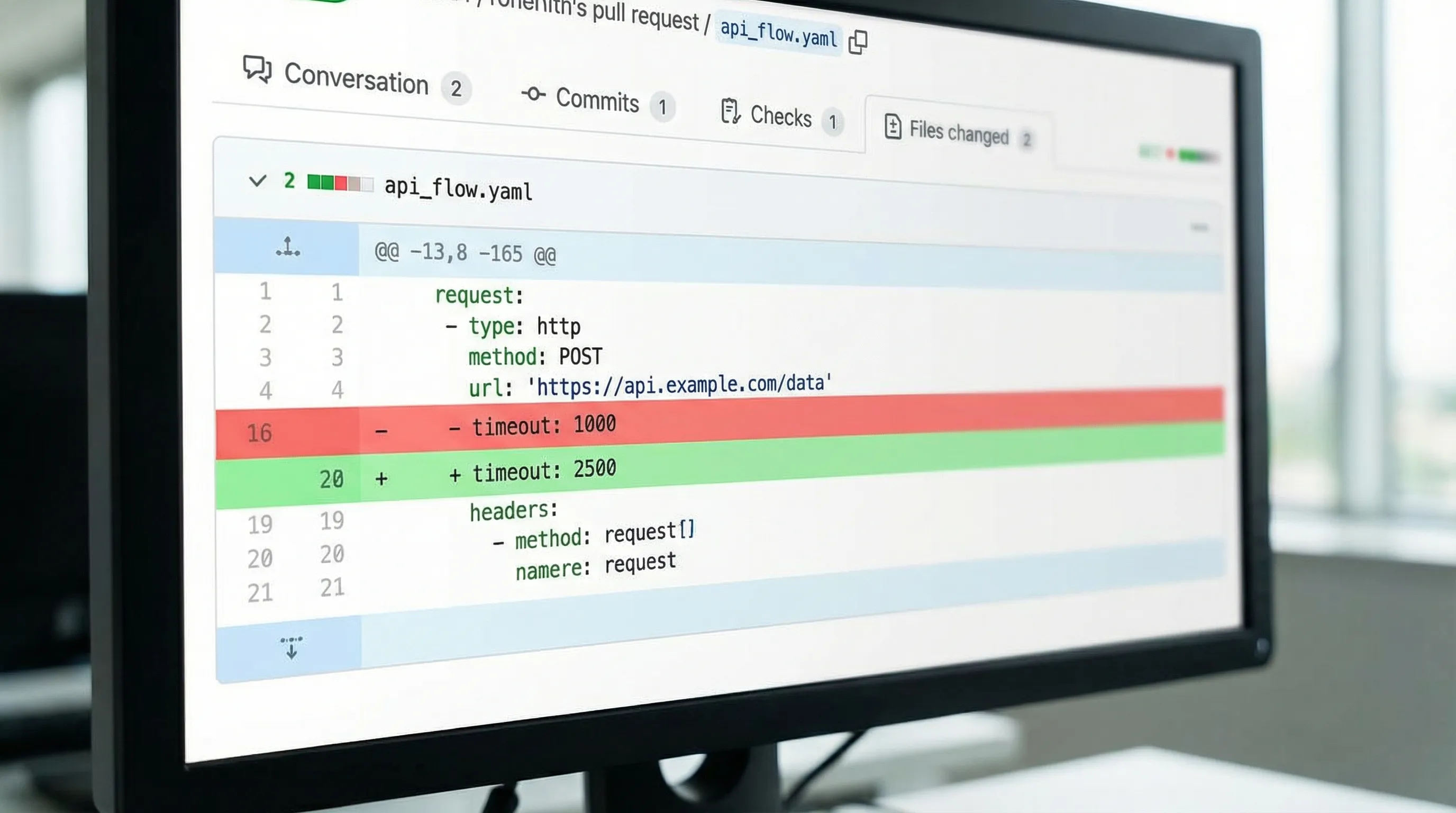
YAML API test file structure: conventions that keep diffs readable
The exact schema depends on your runner (DevTools, custom harness, etc.). The conventions below are deliberately schema-agnostic so you can apply them to any “step-based” YAML flow.
1) Enforce a stable key order in every mapping
YAML mappings are unordered by spec, but humans (and many serializers) treat them as ordered. Pick an order and keep it consistent.
A practical order for step nodes in DevTools flows:
- Step type (
request:,js:,if:,for:,for_each:) name(inside the typed node)method,url(for requests)headersbody/query_paramsdepends_oncode(forjs:nodes)
Why it matters: reviewers build muscle memory. If the headers always appear after url, and depends_on always comes last, they scan faster and miss less.
2) Prefer one logical thing per line (avoid inline maps)
Inline maps look compact, but they create ugly diffs.
Avoid:
headers: {Authorization: "Bearer {{token}}", Accept: application/json}
Prefer:
headers:
Accept: application/json
Authorization: "Bearer {{token}}"
That format diff is stable, and a one-header change is a one-line diff.
3) Sort keys inside “diff magnets” (headers, query params)
The most frequently edited parts of API tests are headers and query strings. Make them alphabetically sorted, always.
query:
include: "profile,teams"
limit: 50
sort: created_at
headers:
Accept: application/json
Content-Type: application/json
X-Request-Id: "{{requestId}}"
If you do not sort, serializer output or manual edits will reorder fields and cause large diffs.
4) Use block scalars for large bodies to prevent reflow diffs
When bodies are non-trivial (especially JSON), use | to keep line breaks stable.
body: |
{
"email": "{{email}}",
"password": "{{password}}"
}
This is usually more diff-friendly than trying to express JSON as YAML mappings, because it avoids style drift (quoted vs unquoted, spacing, ordering).
If your team prefers YAML-native bodies, adopt a formatter and a sorting policy, and enforce it in CI. Without that, YAML-native bodies tend to drift.
5) Quote anything YAML might type-cast
YAML has “surprising” implicit typing in some parsers (for example on, off, yes, no, ISO-like dates). For API testing, treat payloads as data, not YAML types.
Good candidates to always quote:
- IDs with leading zeros
- date-like strings
- strings containing
: - header values
Example:
headers:
If-Match: "0"
X-Feature-Flag: "on"
6) Use clear, stable step names
Step names are how you reference values downstream. Keep them PascalCase, descriptive, and stable.
- request:
name: CreateUser
method: POST
url: '{{BASE_URL}}/v1/users'
...
Clear step names improve:
- references between steps (via
{{CreateUser.response.body.id}}) - targeted retries
- selective execution
- stable diffs when you refactor flows
Keep names PascalCase and descriptive. Avoid "churny" prefixes (like ticket numbers) in step names.
7) Keep step-local variables close to where they are used
The most common readability failure in chained API tests is hidden state. Keep captures and usage adjacent.
A good pattern is:
- request node
js:validation node (validates response and optionally returns computed values)- next request node references upstream values via
{{NodeName.response.body.field}}
This makes the data dependency obvious in review, and depends_on makes the execution order explicit.
Request chaining: conventions for clarity and debuggability
Chaining is where API tests become workflows. It is also where many suites become flaky and hard to review.
Pattern: authenticate once, then scope token usage
Prefer a single auth step early, then explicitly reference the token in later steps.
flows:
- name: AuthAndProfile
steps:
- request:
name: Login
method: POST
url: '{{BASE_URL}}/auth/login'
headers:
Accept: application/json
Content-Type: application/json
body:
email: '{{email}}'
password: '{{password}}'
- js:
name: ValidateLogin
code: |
export default function(ctx) {
const resp = ctx.Login?.response;
if (resp?.status !== 200) throw new Error(`Expected 200, got ${resp?.status}`);
if (!resp?.body?.access_token) throw new Error("access_token missing");
return { validated: true };
}
depends_on: Login
- request:
name: GetProfile
method: GET
url: '{{BASE_URL}}/me'
headers:
Accept: application/json
Authorization: Bearer {{Login.response.body.access_token}}
depends_on: ValidateLogin
- if:
name: CheckProfileStatus
condition: GetProfile.response.status == 200
then: NextStep
else: HandleError
depends_on: GetProfile
Notes:
- Values from earlier steps are referenced directly via
{{Login.response.body.access_token}}. - Keep naming consistent (
Login,GetProfile). Avoid abbreviations likeL,GP, etc.
Pattern: correlation IDs and traceability
When debugging CI failures, correlation IDs save time. Generate one per flow run and attach it to every request if your stack supports it.
flows:
- name: TracedRequests
variables:
- name: requestId
value: '{{uuid()}}'
steps:
- request:
name: ListProjects
method: GET
url: '{{BASE_URL}}/projects'
headers:
X-Request-Id: '{{requestId}}'
Even if assertions fail, your logs and server traces line up.
Pattern: reference only what you need
Passing entire response objects through js: return values creates huge state surfaces and makes diffs meaningless.
Prefer:
- reference specific fields:
{{CreateUser.response.body.id}},{{GetProfile.response.headers.etag}} - use
js:nodes to compute derived values when necessary - avoid returning entire response bodies from
js:nodes unless you are snapshot testing
If you must snapshot, store snapshots under fixtures/ and keep the flow YAML referencing them.
Git diff hygiene: prevent churn before it happens
A surprising amount of “test instability” is actually “file stability” issues: reordering keys, reformatting, and regenerated output.
Adopt a formatter, and run it automatically
Pick one formatting standard and enforce it in pre-commit and CI.
What to enforce:
- 2-space indentation
- no inline maps for request sections
- stable ordering of keys in common blocks (
headers,query,vars)
If your runner exports YAML (for example, converting recorded traffic into a flow), format the exported file immediately and commit the formatted version.
Do not let tools reserialize your files in CI
If your CI pipeline “loads and rewrites” YAML as part of execution, it will slowly destroy diff stability.
Treat YAML flows as source code:
- execute them
- do not rewrite them
YAML anchors: use carefully
YAML anchors can reduce duplication, but they can also make diffs harder to review if overused.
Use anchors only for truly stable blocks like a shared header set:
commonHeaders: &commonHeaders
Accept: application/json
Content-Type: application/json
steps:
- request:
name: CreateItem
method: POST
url: '{{BASE_URL}}/v1/items'
headers:
<<: *commonHeaders
Authorization: Bearer {{Login.response.body.token}}
If your runner or linter does not fully support anchors, skip them and duplicate explicitly. Readability and portability beat cleverness.
Common diff problems and fixes
| Diff problem | What causes it | Convention that fixes it |
|---|---|---|
| Many lines change when one header changes | inline maps, unsorted keys | multi-line headers + alphabetical sort |
| Large “reformat” diffs in request bodies | YAML auto-wrapping or reserialization | block scalars for bodies (` |
| Renaming steps breaks references | names used as identifiers | stable PascalCase name fields |
| Reviewers cannot see data dependencies | references declared far from source | keep js: validation adjacent to the request it validates |
CI/CD integration: keep flows portable and deterministic
A YAML API test file is only “real” once it runs in CI.
Environment separation
Commit non-secret configuration:
# env/staging.yaml
baseUrl: "https://staging.api.example.com"
Keep secrets out of Git (CI secret store, local ignored files). In the flow YAML, reference variables, not raw secrets.
Deterministic retries and timeouts
Retries can hide flakiness and create nondeterministic runtimes. If you use retries:
- make them explicit in YAML
- scope them per step
- keep max attempts low
Also, avoid asserting on unstable fields (timestamps, randomly ordered arrays) unless you normalize or filter.
Parallel execution and test reporting
Once flows are cleanly structured, parallel execution is mostly a runner concern.
If you are replacing Postman/Newman primarily for CI speed and determinism, you will care about:
- parallelism controls
- exit codes
- machine-readable reports (for example JUnit)
DevTools has a CLI-focused CI approach (including JUnit output) described in its guide: Faster CI with DevTools CLI.
Comparison: Postman/Newman vs Bruno vs native YAML flows
Postman and Newman
Postman collections are JSON with tool-specific structure. Newman runs them in CI, but you inherit the same problems:
- diffs are often noisy because collection JSON is not optimized for human review
- changes are frequently UI-driven, then exported
- “simple edits” can touch multiple unrelated parts of the file
If your goal is Git-native review and deterministic change tracking, collection JSON fights you.
Bruno
Bruno improves the Git story by storing requests in files and avoiding a hosted dependency. The trade-off is that you are still in a tool-defined format (Bruno’s own file conventions), and portability depends on that ecosystem.
DevTools’ positioning is different: it emphasizes native YAML flows that can be generated from real traffic (HAR) and then reviewed as code. If you are evaluating the difference specifically vs Bruno, see: DevTools vs Bruno.
Native YAML as the “source of truth”
The practical advantage of a YAML file is not that YAML is fashionable. It is that:
- code review is meaningful
- diffs can be made stable with conventions
- the suite becomes easier to refactor as APIs evolve
The rest is execution details.
A practical checklist for your next PR
- Use stable key ordering for every step.
- Sort
headersandquerykeys. - Use block scalars for non-trivial bodies.
- Quote ambiguous scalars.
- Keep
js:validation nodes close to the request they validate. - Split environments and secrets from flows.
- Format YAML the same way locally and in CI.
Frequently Asked Questions
How do I keep YAML API tests from producing noisy Git diffs? Use stable key ordering, avoid inline maps, sort headers and query params, and format large bodies with block scalars (|). Enforce formatting in pre-commit and CI.
Should API request bodies be YAML mappings or JSON strings in a YAML file? Either can work. For diff stability, JSON in a block scalar is often better because it prevents reordering and style drift. If you use YAML mappings, enforce a formatter and key sorting.
Are YAML anchors a good idea for API test files? Use anchors only for stable, shared blocks (like common headers). Overusing anchors makes reviews harder and reduces portability if some runners or linters do not support merges consistently.
What is the biggest mistake teams make with request chaining? Hidden state. Referencing data from steps that are far away, or passing entire response objects through js: nodes, makes flows hard to review and brittle. Reference only what you need via {{NodeName.response.body.field}} and keep validation adjacent to the request.
How does this differ from Postman/Newman workflows? Postman collections are JSON in a tool-specific structure, and Newman executes that same structure in CI. YAML-first flows tend to be more readable, diffable, and reviewable as code when conventions are enforced.
Turn recorded traffic into reviewable YAML flows
If your starting point is real browser traffic (not hand-written requests), DevTools can convert HAR captures into executable YAML flows you can commit and review in pull requests, then run locally or in CI. See the product overview at dev.tools and the CI guide for running flows as a Newman alternative: Faster CI with DevTools CLI.