 Star on GitHub
Star on GitHub
Testing Microservices APIs: Practical Patterns Beyond the Testing Pyramid
The testing pyramid breaks down fast in microservices. Not because unit tests are “bad”, but because most meaningful microservice failures are distributed: a token minted by one service is rejected by another, a saga gets stuck after an async hop, a cache invalidation never happens, or a request loses trace context and nobody can debug it.
If you are doing API testing for microservices, the goal is not to “climb the pyramid”. The goal is to build a portfolio of tests that gives you fast feedback on PRs, realistic coverage across service boundaries, and enough observability to explain failures.
This guide focuses on practical patterns that scale in real teams:
- Service virtualization to make workflows deterministic and cheap.
- Consumer-driven contracts to protect APIs at team boundaries.
- Workflow tests that intentionally cross service boundaries.
- Docker Compose test environments for repeatable integration runs.
- Trace-based testing with OpenTelemetry to assert distributed behavior, not just HTTP responses.
Examples use native YAML so test artifacts are readable, diffable, and reviewable in pull requests. That is the core workflow difference versus Postman collections and Newman runs (JSON plus scripts), or Bruno (a custom .bru format). With YAML-first flows (for example, in DevTools), you can keep API tests in Git as code and run them locally or in CI without a UI as the source of truth.
1) A better mental model than the testing pyramid
The classic pyramid assumes you can get most confidence from cheap unit tests, then add fewer integration tests, then a tiny number of end-to-end tests. In microservices, your risk is not shaped like that.
Two reasons:
-
The “unit” that fails is often the interaction, not an internal function.
-
The integration surface area is multi-dimensional. Each service has:
- its own contract (API shape, error semantics)
- its dependencies (datastore, queue, other services)
- cross-cutting invariants (auth, idempotency, tracing)
A more useful model is a test portfolio that deliberately covers different failure modes.
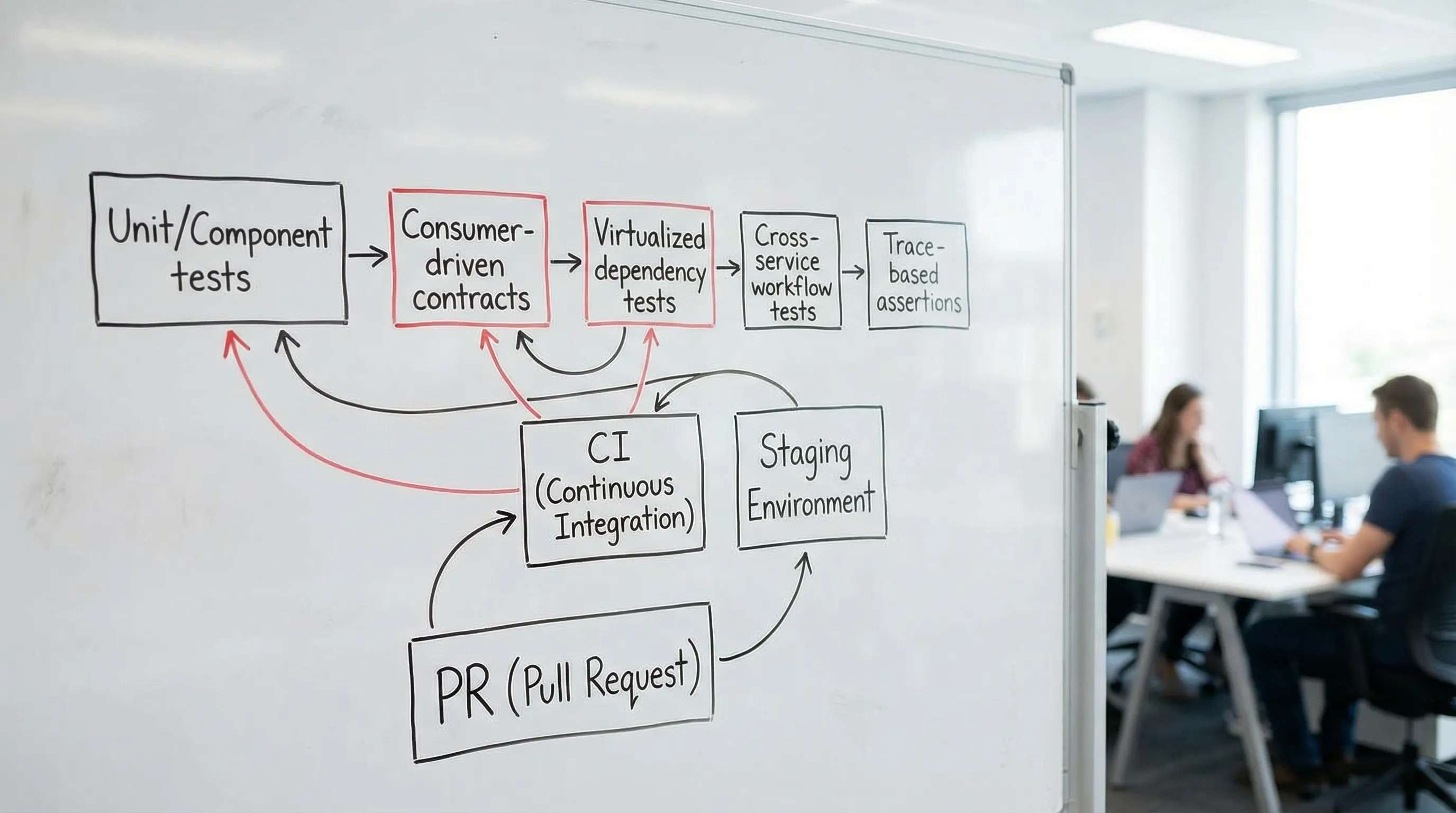
What “beyond the pyramid” means in practice
Instead of arguing “how many end-to-end tests is too many”, start by making these decisions explicit:
- Where do you want API compatibility guarantees (team boundaries)?
- Which dependencies should be virtualized to make workflows deterministic?
- Which business-critical paths require cross-service workflow tests?
- Which distributed invariants should be verified via traces, not just responses?
The patterns below are building blocks. You will likely use all of them, but for different endpoints and at different frequencies.
2) The microservices API testing portfolio (what each test type is for)
The table is intentionally opinionated toward Git-native, CI-friendly testing.
| Test type | What it proves | What it misses | When it should fail | Best artifact format | Typical tooling |
|---|---|---|---|---|---|
| Component/API tests (single service) | Handler logic, validation, persistence contracts | Cross-service behavior, async hops | On PRs to the service | Code + fixtures | language test frameworks, local containers |
| Consumer-driven contract (CDC) | Provider stays compatible with real consumers | Business workflows, latency, infra issues | On PRs to provider and/or consumer | Contract definitions + provider verification reports | Pact ecosystem or equivalent |
| Virtualized dependency workflow tests | Your service behaves correctly given controlled downstream responses | Real downstream behavior and performance | On PRs, nightly | YAML flows + mock config | WireMock/MockServer + YAML runner |
| Cross-service workflow tests | Business paths across service boundaries | Full production topology, rare network failure modes | PR gate for high-risk changes, nightly otherwise | YAML flows + Compose env | YAML runner + ephemeral env |
| Trace-based assertions | Distributed invariants: propagation, span coverage, async hops | Response payload correctness if not asserted separately | PR or nightly, depending on stability | YAML flows + trace queries | OpenTelemetry + Jaeger/Tempo APIs |
A key idea: keep artifacts reviewable. When a test fails in CI, you want the PR diff to show exactly what behavior you encoded.
This is where Postman and Newman often get painful at scale:
- The source of truth tends to be a GUI collection.
- “Tests” drift into JavaScript snippets that are hard to review.
- Diffs are noisy and merges conflict.
Bruno improves the “local-first” story, but it is still a tool-specific format (.bru) rather than native YAML that can be shared across tooling.
YAML-first flows are not automatically “better”, but they are structurally aligned with Git workflows: readable diffs, CODEOWNERS review, branch protection, deterministic CI runs.
3) Consumer-driven contracts: enforce team boundaries without running the world
Microservices fail at boundaries. CDC is the most cost-effective way to keep boundaries safe without booting a full environment for every PR.
3.1 What CDC should encode (and what it should not)
Good CDC captures:
- required fields and their types
- stable semantics of error responses
- pagination, filtering, sorting expectations
- auth and permission error behavior
CDC should avoid:
- “exact payload snapshot” of volatile fields (timestamps, IDs)
- performance and timeouts (better handled separately)
- internal implementation details
If you already have OpenAPI, CDC is not redundant. OpenAPI is a provider-centric spec, CDC is consumer-centric evidence. The best outcome is both.
3.2 CDC workflow (consumer and provider)
A common pattern:
- Consumer publishes contract expectations for the provider.
- Provider verifies those expectations in CI.
- Provider can deploy only if verification passes.
The standard toolchain here is Pact.
Even if you use Pact, you still want the interaction cases to be human-reviewable and stable in Git. Many teams keep a “contract test suite” folder that mirrors consumer use cases.
3.3 Using YAML to keep contract cases readable in Git
Below is a concrete pattern: represent each consumer expectation as a small YAML flow that can run against the provider (or a provider container in CI). The goal is not to replace Pact’s broker or verification model, but to make contract expectations easy to review and to run in any pipeline.
# contracts/catalog/get-product.basic.yaml
version: 1
name: contract.catalog.get_product.basic
vars:
base_url: ${env.CATALOG_BASE_URL}
product_id: "sku-123"
steps:
- name: get_product
request:
method: GET
url: "${vars.base_url}/v1/products/${vars.product_id}"
headers:
accept: application/json
assert:
- status: 200
- header: "content-type"
contains: "application/json"
- jsonpath: "$.id"
equals: "${vars.product_id}"
- jsonpath: "$.price.currency"
equals: "USD"
- jsonpath: "$.price.amount"
type: number
Why this works well in PR review:
- The contract is a few lines of YAML.
- Reviewers can spot breaking changes immediately.
- It is not tied to a Postman UI or collection export.
3.4 Contract tests for errors are where most breaking changes hide
Many “breaking changes” are actually error semantics changes.
# contracts/catalog/get-product.not-found.yaml
version: 1
name: contract.catalog.get_product.not_found
vars:
base_url: ${env.CATALOG_BASE_URL}
product_id: "does-not-exist"
steps:
- name: get_product_not_found
request:
method: GET
url: "${vars.base_url}/v1/products/${vars.product_id}"
headers:
accept: application/json
assert:
- status: 404
- jsonpath: "$.error.code"
equals: "NOT_FOUND"
- jsonpath: "$.error.message"
type: string
If your organization is serious about backwards compatibility, require these checks for every consumer-facing API.
3.5 Provider verification in containerized CI
Provider verification is most useful when it runs in isolation:
- Build provider image.
- Boot provider plus minimal dependencies.
- Run contract suite.
This is a perfect match for “YAML tests in Git + CLI runner in CI” and tends to be simpler to debug than “Newman runs that depend on exported collections + scripts”.
If you already have a YAML-first runner (for example, DevTools) you can run these contract flows the same way you run workflow tests, which keeps operational complexity down.
4) Service virtualization: make workflows deterministic without lying to yourself
Service virtualization is not “mock everything”. It is “virtualize the dependencies you cannot or should not run for this test”.
4.1 When virtualization is the right choice
Virtualize when the dependency is:
- expensive (payments, fraud scoring, SaaS)
- slow or rate-limited
- nondeterministic (ML scoring, external catalogs)
- hard to run locally (vendor systems)
- unsafe to call from CI (real charges, emails)
Do not virtualize when you are trying to validate:
- a real integration (auth provider config, real queue behavior)
- performance characteristics
- production-only routing behavior
The point is to shrink the blast radius of your tests while keeping them meaningful.
4.2 Virtualization patterns that actually scale
Pattern A: Passive stubs
- Return static responses for a given request.
- Great for basic workflow tests.
Pattern B: Stateful scenarios
- A sequence of calls returns different responses.
- Useful for sagas and retries.
Pattern C: Fault injection
- Timeouts, 500s, malformed payloads.
- Critical for resilience testing.
Tooling: WireMock is common and easy to run in Docker. MockServer, Mountebank, Hoverfly are also options.
4.3 Docker Compose: service + virtualized dependency
This Compose file boots:
ordersservice under testwiremockas a virtualized payments provider- a Postgres instance
# compose/orders-with-virtual-payments.yaml
services:
postgres:
image: postgres:16
environment:
POSTGRES_PASSWORD: postgres
POSTGRES_USER: postgres
POSTGRES_DB: orders
ports:
- "5432:5432"
wiremock:
image: wiremock/wiremock:3.6.0
ports:
- "8089:8080"
command:
- "--verbose"
orders:
build:
context: ../services/orders
environment:
DATABASE_URL: postgres://postgres:postgres@postgres:5432/orders
PAYMENTS_BASE_URL: http://wiremock:8080
depends_on:
- postgres
- wiremock
ports:
- "8080:8080"
This is intentionally boring. Boring is good in CI.
4.4 Configure mocks as part of the test, not as an implicit side file
A frequent virtualization failure mode is “mocks drift from what the test thinks is happening”. You can reduce drift by having the test configure the mock behavior explicitly.
WireMock exposes an admin API to create stub mappings. You can drive that from YAML.
# flows/orders/create-order.with-virtual-payments.yaml
version: 1
name: orders.create_order.virtual_payments
vars:
orders_base_url: http://localhost:8080
wiremock_admin: http://localhost:8089/__admin
run_id: ${env.RUN_ID}
steps:
- name: stub_payments_authorize
request:
method: POST
url: "${vars.wiremock_admin}/mappings"
headers:
content-type: application/json
body:
json: |
{
"request": { "method": "POST", "url": "/v1/authorize" },
"response": {
"status": 200,
"headers": { "Content-Type": "application/json" },
"jsonBody": { "authorized": true, "authId": "auth-${RUN_ID}" }
}
}
assert:
- status: 201
- name: create_order
request:
method: POST
url: "${vars.orders_base_url}/v1/orders"
headers:
content-type: application/json
x-run-id: "${vars.run_id}"
body:
json: |
{ "items": [{"sku": "sku-123", "qty": 1}] }
assert:
- status: 201
- jsonpath: "$.id"
type: string
Notes:
- The stub includes
${RUN_ID}in the JSON body above as a placeholder. In practice you should template it using your runner’s variable syntax (the important point is that the mapping is created per run, not shared globally). - This pattern keeps mock behavior in the same PR diff as the test.
4.5 Virtualization for resilience (timeouts, retries, idempotency)
If your service has retry logic, you want tests that validate:
- the retry actually happens
- you are not duplicating side effects
- idempotency keys work
With virtualization, you can force timeouts or 500s deterministically, then assert your service responds correctly.
Postman and Newman can do this, but it often ends up hidden in scripts or in “environment setup” steps that are hard to maintain. YAML makes the sequence explicit.
5) Workflow testing across service boundaries: test business paths, not endpoints
Single-endpoint tests rarely catch the bugs that hurt users. In microservices, “end-to-end” usually means “end-to-end across APIs”, not “drive a browser”.
The core technique is request chaining:
- call service A
- extract an ID or token
- call service B using that extracted value
- validate invariants at each hop
With YAML-first workflows, chaining remains readable. With Postman/Newman, chaining often becomes JavaScript-heavy and brittle.
5.1 Workflow tests need a boundary decision
You have to decide what “end” means:
- API gateway only?
- gateway + internal services?
- include async queue consumption?
- include external providers?
A pragmatic pattern:
- Use virtualization for true externals.
- Use real services for your own boundaries.
- Assert trace coverage for async hops.
5.2 A realistic cross-service workflow: order placement
Assume a path:
checkout-apicreates an orderpaymentsauthorizesinventoryreservesordersbecomesCONFIRMED
You want one workflow test that validates the end-to-end state machine, plus smaller contract tests per service.
# flows/checkout/place-order.confirmed.yaml
version: 1
name: checkout.place_order.confirmed
vars:
checkout_base_url: ${env.CHECKOUT_BASE_URL}
orders_base_url: ${env.ORDERS_BASE_URL}
run_id: ${env.RUN_ID}
steps:
- name: place_order
request:
method: POST
url: "${vars.checkout_base_url}/v1/checkout"
headers:
content-type: application/json
x-run-id: "${vars.run_id}"
body:
json: |
{
"customerId": "c-123",
"items": [{"sku": "sku-123", "qty": 1}],
"paymentMethod": {"type": "card", "token": "tok_test"}
}
assert:
- status: 202
- jsonpath: "$.orderId"
type: string
extract:
order_id: "$.orderId"
- name: get_order_until_confirmed
request:
method: GET
url: "${vars.orders_base_url}/v1/orders/${steps.place_order.extract.order_id}"
headers:
accept: application/json
x-run-id: "${vars.run_id}"
assert:
- status: 200
- jsonpath: "$.id"
equals: "${steps.place_order.extract.order_id}"
- jsonpath: "$.state"
in: ["PENDING", "CONFIRMED"]
Two important points for experienced teams:
-
You should make eventual consistency explicit. Don’t assert
CONFIRMEDimmediately unless the architecture guarantees it. Instead, poll with a bounded timeout. -
Avoid “global shared fixtures”. Use a unique
run_idand isolate test-created data.
If your YAML runner supports polling loops, encode it there. If not, keep the logic simple: a small loop node, a bounded retry, or a dedicated “wait until state” endpoint.
5.3 Make idempotency and correlation first-class in workflows
Workflow tests should always cover idempotency keys for side-effecting requests.
# flows/checkout/place-order.idempotency.yaml
version: 1
name: checkout.place_order.idempotency
vars:
checkout_base_url: ${env.CHECKOUT_BASE_URL}
run_id: ${env.RUN_ID}
idem_key: "idem-${env.RUN_ID}"
steps:
- name: place_order_first
request:
method: POST
url: "${vars.checkout_base_url}/v1/checkout"
headers:
content-type: application/json
idempotency-key: "${vars.idem_key}"
x-run-id: "${vars.run_id}"
body:
json: |
{ "customerId": "c-123", "items": [{"sku": "sku-123", "qty": 1}] }
assert:
- status:
in: [200, 202]
extract:
order_id: "$.orderId"
- name: place_order_second_same_key
request:
method: POST
url: "${vars.checkout_base_url}/v1/checkout"
headers:
content-type: application/json
idempotency-key: "${vars.idem_key}"
x-run-id: "${vars.run_id}"
body:
json: |
{ "customerId": "c-123", "items": [{"sku": "sku-123", "qty": 1}] }
assert:
- status:
in: [200, 202]
- jsonpath: "$.orderId"
equals: "${steps.place_order_first.extract.order_id}"
This kind of test is painful to keep clean in Postman/Newman if it relies on scripts and hidden state. In YAML it reads like a spec.
5.4 Keep workflow tests small and composable
The most scalable approach is not “one massive end-to-end flow”. It is:
- a small number of workflows for core business paths
- shared helper flows for auth and setup
- strict cleanup patterns
In YAML-first setups, this often looks like:
flows/
auth/
login.yaml
checkout/
place-order.confirmed.yaml
place-order.idempotency.yaml
contracts/
catalog.get-product.basic.yaml
compose/
stack.test.yaml
otel/
collector.yaml
That structure maps to how teams review PRs: services own their contracts, product teams own workflows.
6) Docker Compose test environments: reproducible integration without Kubernetes
A lot of microservices API testing pain comes from running tests against “some shared dev environment”:
- data is polluted
- versions drift
- failures are non-reproducible
Compose is not a perfect environment, but it is a great fit for deterministic integration tests when you prioritize:
- repeatability
- local debugging
- CI parity
See the official Docker Compose docs for mechanics, but the important part is how you design the environment.
6.1 Compose design rules for test environments
Rules that reduce flakiness:
- Pin images and base layers (no floating tags).
- Expose only what tests need.
- Use health checks and wait for readiness.
- Prefer ephemeral volumes or seeded snapshots.
- Make test data creation part of the flow, not pre-baked state.
6.2 A Compose stack for cross-service workflow tests (plus tracing)
This example boots a small stack:
checkout-api,orders,inventorywiremockfor external paymentsotel-collector+jaegerso you can do trace-based assertions
# compose/stack.test.yaml
services:
wiremock:
image: wiremock/wiremock:3.6.0
ports:
- "8089:8080"
jaeger:
image: jaegertracing/all-in-one:1.55
ports:
- "16686:16686" # UI
- "16685:16685" # query API
- "4317:4317" # OTLP gRPC
otel-collector:
image: otel/opentelemetry-collector-contrib:0.96.0
command: ["--config=/etc/otelcol/config.yaml"]
volumes:
- ../otel/collector.yaml:/etc/otelcol/config.yaml:ro
depends_on:
- jaeger
checkout-api:
build: ../services/checkout-api
environment:
PAYMENTS_BASE_URL: http://wiremock:8080
OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:4317
OTEL_SERVICE_NAME: checkout-api
ports:
- "8080:8080"
depends_on:
- wiremock
- otel-collector
orders:
build: ../services/orders
environment:
OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:4317
OTEL_SERVICE_NAME: orders
ports:
- "8081:8080"
depends_on:
- otel-collector
inventory:
build: ../services/inventory
environment:
OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:4317
OTEL_SERVICE_NAME: inventory
ports:
- "8082:8080"
depends_on:
- otel-collector
This is a powerful pattern because you can reproduce a CI failure locally by running the same Compose stack and the same YAML flow.
6.3 OpenTelemetry Collector config (YAML) for test stacks
Collector config is real YAML, and it is worth keeping in Git next to the tests.
# otel/collector.yaml
receivers:
otlp:
protocols:
grpc:
processors:
batch:
exporters:
otlp:
endpoint: jaeger:4317
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
For test environments:
- Prefer always-on sampling (or very high sampling) so your test assertions do not fail due to sampling.
- Keep the pipeline minimal. You want fewer moving parts.
7) Trace-based testing with OpenTelemetry: assert distributed behavior
HTTP-level assertions tell you what the client saw. Traces tell you what actually happened across services.
Trace-based testing is not about checking every span attribute. It is about verifying distributed invariants that are otherwise invisible.
If your services already emit OTel traces, you can query a tracing backend to assert:
- trace context propagated across boundaries
- the workflow produced expected spans (including async work)
- error paths are correctly tagged
- a downstream call was attempted exactly once (idempotency)
Reference: OpenTelemetry documentation.
7.1 What makes trace assertions stable (and what makes them flaky)
Stable trace assertions:
- assert existence of specific spans by operation name
- assert parent-child relationships for key edges
- assert error tags for known failure injections
Flaky trace assertions:
- exact duration thresholds (too environment-dependent)
- asserting every attribute (instrumentation changes frequently)
- relying on sampled traces in low-sampling environments
7.2 A pragmatic approach: tie traces to a run identifier
Your workflow tests should send a deterministic identifier that services copy into span attributes.
Common options:
x-run-idheaderx-request-idheader- a field inside the request body (less ideal)
Then you query the tracing backend for that identifier.
7.3 Querying Jaeger’s API from a YAML workflow
Jaeger exposes an HTTP query API. That means your test runner can fetch traces like any other API call.
Jaeger query API details vary by version, but the common shape is:
- query traces for a service
- filter by tags
- inspect returned trace data
Jaeger’s project docs are the right reference point for your exact deployment: Jaeger documentation.
Below is an example pattern (adapt parameters to your Jaeger version and indexing behavior).
# flows/checkout/place-order.trace-assertions.yaml
version: 1
name: checkout.place_order.trace_assertions
vars:
checkout_base_url: http://localhost:8080
jaeger_query: http://localhost:16685
run_id: ${env.RUN_ID}
steps:
- name: place_order
request:
method: POST
url: "${vars.checkout_base_url}/v1/checkout"
headers:
content-type: application/json
x-run-id: "${vars.run_id}"
body:
json: |
{ "customerId": "c-123", "items": [{"sku": "sku-123", "qty": 1}] }
assert:
- status:
in: [200, 202]
- name: query_traces_by_run_id
request:
method: GET
url: "${vars.jaeger_query}/api/traces"
query:
service: checkout-api
tags: '{"x.run_id":"${vars.run_id}"}'
limit: "5"
assert:
- status: 200
- jsonpath: "$.data"
type: array
From there, you can assert that at least one trace contains spans you care about. Keep the checks coarse at first, then tighten.
- name: assert_trace_contains_critical_spans
request:
method: GET
url: "${vars.jaeger_query}/api/traces"
query:
service: checkout-api
tags: '{"x.run_id":"${vars.run_id}"}'
limit: "1"
assert:
- status: 200
- jsonpath: "$.data[0].spans"
type: array
- jsonpath: "$.data[0].spans[*].operationName"
contains: "POST /v1/checkout"
- jsonpath: "$.data[0].spans[*].operationName"
contains: "payments.authorize"
- jsonpath: "$.data[0].spans[*].operationName"
contains: "inventory.reserve"
This is the key idea: use trace queries as another API in your workflow.
7.4 Trace-based assertions for async workflows
Microservices often include asynchronous hops:
- message queues
- background jobs
- outbox patterns
A pure HTTP workflow test may only see “202 Accepted”. Trace assertions can verify that the async handler ran.
Two practical patterns:
- Query traces until you observe the async span, with a bounded timeout.
- Assert that the producer span has a link or attribute that references the async consumer.
If your tracing backend is eventually consistent, build polling into the test. Treat “trace not indexed yet” as a retryable condition.
7.5 Using fault injection + traces to validate resilience
Service virtualization lets you inject failures. Traces let you prove the system responded correctly.
Example: force payments to timeout.
- The workflow asserts the HTTP response is a 502/503 (or a domain-specific error).
- The trace assertion checks:
- the downstream span is marked error
- retries happened (bounded)
- the order was not created twice
This combination catches classes of bugs that neither contract tests nor simple endpoint tests will find.
8) How this fits into Git workflows and CI/CD
The patterns above only pay off if they integrate into how you ship code.
8.1 Keep YAML tests reviewable and deterministic
For experienced teams, this is the real win:
- Test changes are just code changes.
- PR diffs show behavior changes.
- CI runs are reproducible.
This is where YAML-first tools differ structurally from Postman/Newman:
- Postman collections are exportable, but most teams still author in the UI.
- Newman executes, but the maintenance burden is in scripts and collection state.
And versus Bruno:
- Bruno is local-first and Git-friendly, but the format is still tool-specific.
- Native YAML makes it easier to keep tests portable and to reuse YAML tooling (linters, formatters, policy checks).
8.2 A practical repo layout for microservices API testing
One layout that maps well to ownership:
api-tests/
contracts/
catalog/
payments/
flows/
checkout/
orders/
compose/
stack.test.yaml
orders-with-virtual-payments.yaml
otel/
collector.yaml
env/
local.env
ci.env
Ownership model:
- Service teams own their contract folders.
- Product or platform teams own cross-service flows and Compose stacks.
8.3 Suggested execution cadence (what runs when)
Avoid “run everything always”. Microservices suites grow quickly.
A pragmatic cadence:
- On every PR:
- unit/component tests
- provider contract verification
- virtualized dependency workflows for touched services
- On merge to main:
- a small number of cross-service workflows in an ephemeral environment
- Nightly:
- broader workflow suite
- resilience tests (fault injection)
- deeper trace-based assertions
The point is to align cost with risk.
8.4 Determinism guidelines that matter specifically in microservices
If you only take one operational lesson: make concurrency and shared state explicit.
For CI stability:
- Generate unique identifiers per run (
RUN_ID) and pass them through requests. - Avoid relying on “the latest record” queries.
- Keep cleanup explicit (delete created entities).
- Ensure parallel test runs don’t share a database unless isolated per run.
These are not “YAML tips”, they are distributed systems test hygiene.
9) Putting it all together: a concrete “beyond the pyramid” recipe
If you are starting from scratch, this sequence tends to work:
Step 1: Add consumer-driven contracts to every shared API
- Start with 3 to 10 critical interactions per consumer.
- Cover error semantics.
- Make provider verification a PR gate.
Step 2: Add virtualization for external dependencies
- Replace calls that cost money or cause side effects.
- Configure stubs as part of the workflow.
- Add fault injection cases for retries and idempotency.
Step 3: Add a small number of cross-service workflows
- One per critical business capability.
- Keep them short, assert invariants at each hop.
- Run them in an ephemeral Compose stack.
Step 4: Add trace-based assertions for distributed invariants
- Propagation across boundaries.
- Async hop executed.
- Retries bounded and visible.
This is the point where microservices testing stops being “a bunch of HTTP requests” and becomes “a verification harness for distributed behavior”.
10) Why YAML-first workflows are a good fit for these patterns
None of the patterns above require a specific tool, but they do require a specific workflow:
- Tests must be code-reviewed.
- They must be runnable headlessly.
- They must be deterministic.
- They must be portable across local and CI.
In practice, teams struggle with this when tests are UI-authored and exported later.
A YAML-first approach (for example, DevTools’ YAML flows) aligns with the way experienced teams already operate:
- PR review is the governance layer.
- Git history is the audit trail.
- CI is the enforcement layer.
If you are replacing Postman/Newman, the key shift is not “a different runner”. It is making the test artifact itself a first-class, readable, versioned spec.
That is what unlocks the microservices patterns in this guide, especially when you start combining virtualization, cross-service workflows, and trace queries into a single deterministic pipeline.