 Star on GitHub
Star on GitHub
Postman Alternative for Git-First Teams: YAML, PRs, Runner
If your team lives in pull requests, a Postman workspace often becomes the odd one out: tests exist as UI state, reviews happen out of band, and CI runs feel like a fragile “export then pray” step.
A Postman alternative for Git-first teams is less about having a nicer API client, and more about turning API tests into reviewable code: plain text definitions, deterministic request chaining, and a runner that behaves like any other CI tool.
This article outlines what to optimize for (YAML, PR review, CI determinism), where Postman, Newman, and Bruno tend to pinch, and what a Git-native workflow looks like when your tests are multi-request flows instead of single endpoints.
What Git-first teams actually need from an API testing tool
Git-first constraints are pretty simple:
- A stable, human-readable format so changes can be reviewed like code.
- Deterministic execution so CI failures are reproducible locally.
- First-class request chaining because most real regressions live between endpoints.
- CI-native ergonomics (exit codes, JUnit/JSON reports, parallelism, pinned versions).
- Minimal “magic state” hidden in a GUI.
Postman (the app) is great for interactive exploration, but Git-first teams typically hit friction on the “definition of record” question: is the source of truth the collection JSON, the environment JSON, or what someone clicked in a workspace five minutes ago?
A YAML-first approach, like DevTools, is built around making the answer boring: the source of truth is a text file in your repo.
Where Postman + Newman typically break down in PR-driven workflows
1) Collections are versionable, but not pleasant to review
Yes, Postman collections are JSON and can be committed. In practice:
- Diffs are noisy (reordered keys, regenerated IDs, metadata churn).
- “What changed?” is harder to answer than it should be.
- Script-heavy logic (pre-request/test scripts) hides behavior in code blobs embedded in JSON.
That is not a moral failing of JSON, it is a tooling mismatch: your reviewers want a code review experience, not a data export review.
2) Newman makes CI possible, not necessarily clean
Newman solves “run the collection in CI,” but most teams still end up building glue:
- environment selection conventions
- secret injection rules
- report normalization
- retry policies
- parallelization and sharding
And the core artifact is still a Postman collection. If you have ever blocked a PR because a collection export rewrote half the file, you already know the cost.
3) UI-first tools encourage UI-only collaboration
Postman’s collaboration model is anchored in workspaces and permissions. Git-first teams prefer:
- CODEOWNERS
- branch protections
- PR templates
- mandatory CI checks
- artifact retention
When the “real” test suite lives in a UI, PR gates tend to become indirect (run Newman off exported collections, hope the exports are current, and trust that nobody changed a workspace without committing the result).
Bruno: closer to Git, but still a custom format problem
Bruno is explicitly Git-friendly, which is a big step in the right direction. The main trade-off for strict Git-first teams is that you are still adopting a tool-specific representation (a Bruno collection format and conventions) rather than leaning on native YAML as a directly reviewable contract.
This matters when you want your API tests to behave like other infrastructure code:
- YAML conventions you already enforce (formatting, linting, key ordering) can apply.
- The files remain understandable even if the original tool is not running.
- You can generate, edit, and validate flows with standard text tooling.
If you are choosing a long-lived replacement for Postman/Newman, “is the test definition portable text?” is a more important question than “does the UI feel familiar?”
What “YAML-first” changes in practice
YAML-first is not “we store data in YAML.” It is:
- Tests are authored and maintained as YAML files (not exports).
- PR review is the primary collaboration mechanism.
- The runner is the product surface area, because CI is where regressions get caught.
DevTools’ model is: capture real traffic (for example via HAR), convert it into executable YAML flows, commit those flows, and run them locally or in CI.
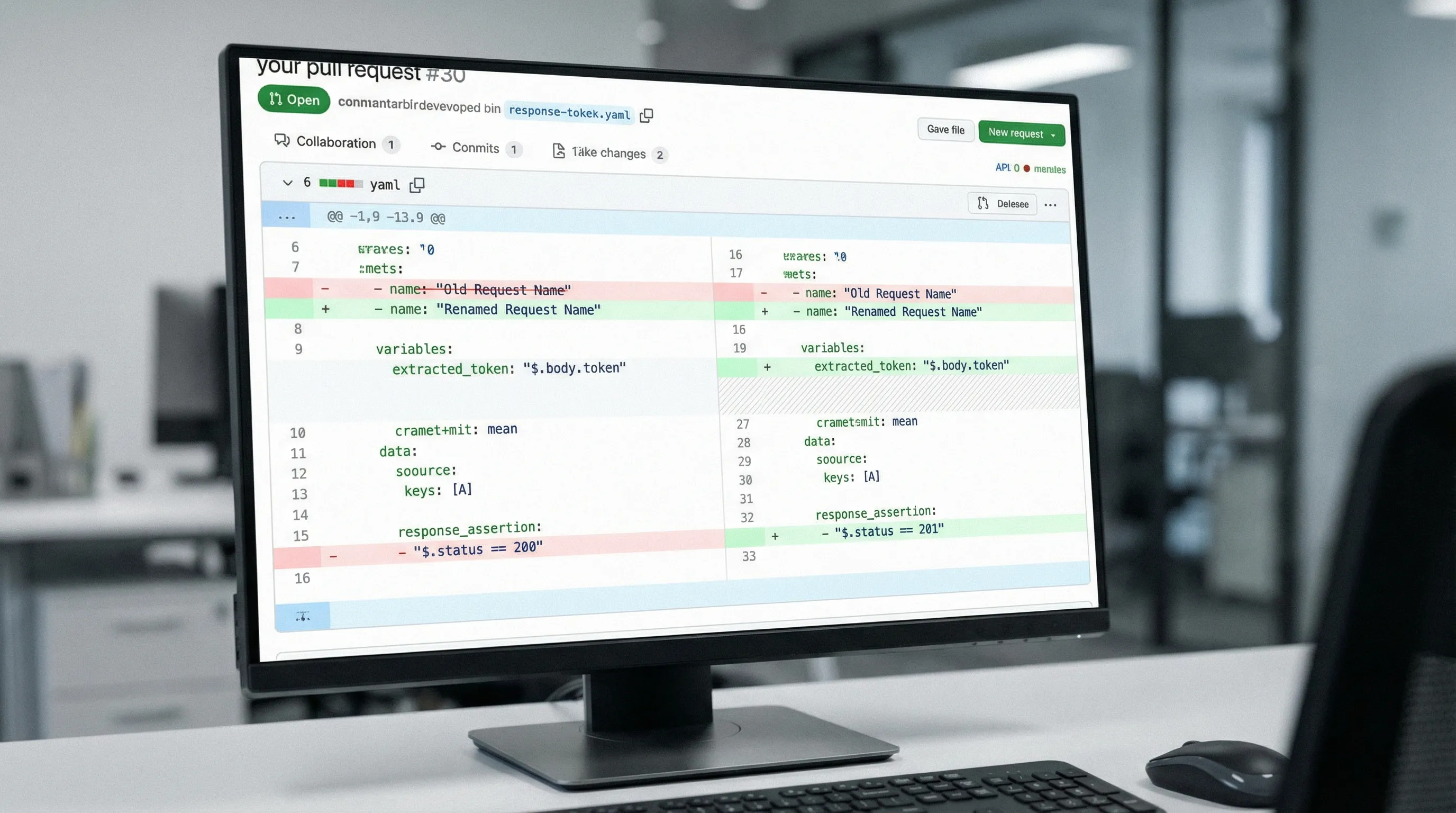
A simplified YAML flow example (multi-step, chained)
Below is an intentionally simplified example of the kind of PR-reviewable flow Git-first teams gravitate toward. The key properties are explicit chaining, environment-driven base URLs, and assertions that focus on invariants.
name: user-lifecycle
vars:
base_url: ${BASE_URL}
steps:
- name: login
request:
method: POST
url: ${base_url}/auth/login
headers:
content-type: application/json
body:
username: ${E2E_USER}
password: ${E2E_PASS}
extract:
token: $.access_token
assert:
status: 200
jsonpath:
- path: $.access_token
exists: true
- name: create_user
depends_on: [login]
request:
method: POST
url: ${base_url}/users
headers:
authorization: Bearer ${steps.login.token}
content-type: application/json
body:
email: user+${RUN_ID}@example.test
extract:
user_id: $.id
assert:
status: 201
jsonpath:
- path: $.id
type: string
- name: get_user
depends_on: [create_user]
request:
method: GET
url: ${base_url}/users/${steps.create_user.user_id}
headers:
authorization: Bearer ${steps.login.token}
assert:
status: 200
jsonpath:
- path: $.email
equals: user+${RUN_ID}@example.test
- name: delete_user
depends_on: [get_user]
request:
method: DELETE
url: ${base_url}/users/${steps.create_user.user_id}
headers:
authorization: Bearer ${steps.login.token}
assert:
status:
in: [200, 204]
Why this structure works well in PRs:
- The dependency chain is explicit (
depends_on), so reviewers understand sequencing. - Variable extraction is visible and local to the step.
- Assertions are readable and scoped per step.
- The run is parameterized (base URL, credentials, run ID) so it is environment-safe.
If someone changes auth, response shape, or required headers, the diff tells the story.
Capturing real flows (HAR) without importing UI state into your repo
A common anti-pattern in Postman-based orgs is rebuilding flows manually in a GUI, then maintaining them by hand as the product evolves.
Git-first teams increasingly do the opposite:
- record real browser traffic for the exact workflow that users run
- convert that traffic into a YAML flow
- delete the noise, parameterize secrets, and make dependencies explicit
This workflow is especially useful when your API is driven by a web UI and the “real” behavior includes cookies, CSRF headers, pagination cursors, or subtle ordering constraints.
If you want a concrete, harmless target to practice on, pick any modern web app with visible network calls. Even a community tool like TableCommander is sufficient to remind you how quickly a browser session turns into multiple chained requests with state that must be extracted and replayed deterministically.
The important part is what happens after capture:
- remove third-party requests
- drop volatile headers
- replace recorded tokens with a login step that extracts fresh tokens
- make IDs and cursors flow through explicit variables
That produces tests that are repeatable, rather than “a replay of yesterday’s session.”
PR review mechanics: how YAML changes the social contract
If your API tests are text-first, you can apply normal engineering governance.
CODEOWNERS and review boundaries
A simple pattern:
- service team owns
flows/<service>/** - platform team owns CI wiring and runner versions
- security owns
env/*.exampleand secret injection rules
With UI-stored tests, that separation is awkward. With YAML in-repo, it is natural.
Review comments become specific, not generic
Reviewers can leave concrete comments like:
- “This assertion will flake because it checks an unordered array position.”
- “You are extracting
idfrom$.data.id, but the response shows$.id.” - “This step should depend on
create_user, notlogin.”
That kind of review is hard when the main artifact is a workspace state or a big JSON export.
You can enforce determinism with normal tooling
Because YAML is plain text, you can add lightweight gates:
- formatting rules that keep diffs stable
- “no secrets in repo” scanners
- lint checks for volatile headers
- policy checks like “every create has a cleanup”
The point is not to build bureaucracy, it is to make CI failures boring.
CI/CD integration: treat the runner like any other build tool
The main difference between “tests stored in Git” and “tests that behave well in CI” is the runner contract.
For Git-first teams, a runner must:
- return consistent exit codes
- emit machine-readable reports (JUnit/JSON)
- support parallel execution without shared mutable state
- be easy to pin to an exact version
DevTools positions itself as a local-first CLI runner for YAML flows, so the same command you run locally is what your CI runs.
A minimal GitHub Actions sketch (runner + reports)
This is intentionally schematic (adapt to your repo and runner install method), but it shows the shape Git-first teams want: pinned tool version, deterministic command, and artifacts.
name: api-tests
on:
pull_request:
jobs:
smoke:
runs-on: ubuntu-24.04
steps:
- uses: actions/checkout@v4
- name: Run YAML flows (smoke)
env:
BASE_URL: ${{ secrets.BASE_URL }}
E2E_USER: ${{ secrets.E2E_USER }}
E2E_PASS: ${{ secrets.E2E_PASS }}
run: |
devtools run flows/smoke \
--report-junit out/junit.xml \
--report-json out/report.json
- name: Upload test reports
uses: actions/upload-artifact@v4
with:
name: api-test-reports
path: out/
The win is not the YAML syntax, it is the workflow outcome:
- PR runs are automatic.
- Failures show up where developers work.
- The artifacts are auditable.
Request chaining: the part GUI collections usually hide
Most production regressions are not “GET /health returned 500.” They are:
- auth token shape changed, downstream calls break
- create returns an ID, read endpoint expects a different path segment
- webhook delivery is delayed, polling logic is wrong
- permission checks differ across endpoints
Chaining forces you to model those dependencies explicitly.
Practical chaining patterns that stay deterministic
A few patterns that survive CI:
- Extract only what you need (token, ID, cursor), avoid copying entire blobs forward.
- Generate unique identifiers per run (
RUN_ID) to prevent test collisions in parallel. - Make cleanup explicit (delete what you create), so reruns do not accumulate state.
- Assert invariants, not presentations (types, presence, subset matches).
If you are coming from Postman scripting, this often means moving logic from ad hoc JavaScript to declarative extraction and assertions, and using script nodes only when you truly need computation.
Choosing a Postman alternative: a quick decision table for Git-first teams
This table is not a feature checklist, it is about operational fit for PR-driven orgs.
| Criterion (Git-first) | Postman + Newman | Bruno | DevTools (YAML-first) |
|---|---|---|---|
| Source of truth is pleasant to review in PRs | Often noisy JSON exports | Better, but tool-specific format | Native YAML flows designed for diffs |
| CI runner is the primary workflow | Newman works, but tied to collections | Possible, depends on setup | CLI runner is central |
| Multi-step request chaining is first-class | Possible, often script-heavy | Possible | Core concept (flows) |
| Portability across teams and pipelines | Export/import workflows | Portable within Bruno ecosystem | YAML in Git, repo-native |
The key question for experienced teams: “Will we still trust and understand these tests in 18 months, when half the team has changed?”
Text-first, Git-reviewed workflows tend to age better than UI-anchored ones.
A migration strategy that does not stall your delivery
Most teams cannot stop everything to “rewrite tests.” A pragmatic migration usually looks like:
- Keep Postman for exploratory/manual work in the short term.
- Move CI gates first: pick a small set of smoke workflows and make them YAML flows.
- Migrate high-value chains (auth + core CRUD + critical business workflows) next.
- Only then decide whether to fully decommission Newman.
What makes migrations succeed is not perfect conversion, it is eliminating the UI as the system of record for CI.
If you want a starting point tailored to this exact change, DevTools maintains a dedicated guide for teams that are migrating away from Postman collections into Git-native YAML flows.
The bottom line
If you are searching for a Postman alternative because of pricing, licensing, or UI friction, you can easily end up swapping one tool for another and keeping the same workflow problems.
Git-first teams get the biggest payoff by changing the workflow itself:
- YAML as the review artifact
- PRs as the collaboration surface
- a deterministic runner as the source of truth
- explicit request chaining for real regressions
That combination is what turns API testing from “a shared workspace” into “part of engineering.”