 Star on GitHub
Star on GitHub
JUnit Reports for API Tests: Make GitHub Actions Show Failures Cleanly
CI failures that you cannot see are failures you will not fix quickly.
For API tests, the fastest path from red build to merged PR is usually: a single failing request, a deterministic reproduction path, and a failure message that points to the exact step. JUnit XML is still the most interoperable format for that, especially in GitHub Actions where you can surface failures as a first-class “test report” instead of forcing everyone to download logs.
This post shows how to structure JUnit reports for API tests so GitHub Actions renders clean, actionable failures, how to publish them, and how to preserve correct exit codes while still uploading artifacts.
What “clean failures” looks like in GitHub Actions
For experienced teams, “clean” means:
- A PR check that shows a failed test list with names that match your API flow steps.
- One click from the failed test to the exact request definition in Git (YAML).
- A short failure reason (timeout, auth, assertion, network), not a 5,000-line dump.
- Full debug material stored as artifacts when you actually need it.
JUnit is the bridge between your runner and GitHub’s reporting ecosystem (checks, summaries, annotations), regardless of whether you execute flows with DevTools, Newman, a homegrown Go runner, or something else.
Make JUnit testcases map to request names and steps
GitHub (and most JUnit viewers) only know about:
testsuite(grouping)testcase(a single test)failureorerrornodes (why it failed)
So your job is to decide what identity you want to preserve.
Recommended naming scheme (stable, diffable, grep-friendly)
Use names that correspond to what reviewers see in Git:
- testsuite name: flow file path, or a logical flow name
- testcase name: step
namethat is stable in YAML - testcase classname (optional): flow name, or
service.areagrouping
The important part is that a failed testcase name should be searchable in the repo.
YAML flow convention: stable step names
With YAML-first API tests, you can make step identity explicit and keep it stable across refactors. Even if you reorder requests or adjust assertions, a stable name keeps the JUnit mapping consistent.
Here is an illustrative pattern showing request chaining and stable step identity:
# flows/auth/profile.yaml
workspace_name: Auth Profile
env:
BASE_URL: https://api.example.com
flows:
- name: AuthProfile
steps:
- request:
name: Login
method: POST
url: '{{BASE_URL}}/v1/login'
headers:
Content-Type: application/json
body:
email: '{{EMAIL}}'
password: '{{PASSWORD}}'
- js:
name: ValidateLogin
code: |
export default function(ctx) {
if (ctx.Login?.response?.status !== 200) throw new Error("Login failed");
if (!ctx.Login?.response?.body?.token) throw new Error("No token");
return { validated: true };
}
depends_on: Login
- request:
name: GetProfile
method: GET
url: '{{BASE_URL}}/v1/me'
headers:
Authorization: 'Bearer {{Login.response.body.token}}'
depends_on: Login
- js:
name: ValidateProfile
code: |
export default function(ctx) {
if (ctx.GetProfile?.response?.status !== 200) throw new Error("Expected 200");
if (!ctx.GetProfile?.response?.body?.id) throw new Error("Missing id");
return { validated: true };
}
depends_on: GetProfile
If Login fails, the JUnit testcase should be named Login, not "Iteration 1" or "POST /v1/login (2)". If GetProfile fails, you want to see GetProfile in GitHub Actions.
This is one of the practical advantages over UI-locked Postman collections and custom formats: the step identity lives in Git as native YAML, so it can be reviewed and kept stable like code.
Example JUnit XML snippet (what GitHub Actions will display)
A minimal, useful JUnit file usually has:
- suite name
- testcase name
- duration (
time) - one failure node with a compact message
- optional
system-outfor a short context line
Example (single failed step due to auth):
<?xml version="1.0" encoding="UTF-8"?>
<testsuite name="flows/auth/profile.yaml" tests="2" failures="1" errors="0" time="1.284">
<testcase classname="AuthProfile" name="Login" time="0.412" />
<testcase classname="AuthProfile" name="GetProfile" time="0.872">
<failure type="auth" message="auth: expected 200, got 401 (missing/expired token)">
Request: GET /v1/me
Assertion: status == 200
Hint: verify EMAIL/PASSWORD secrets and token chaining
</failure>
<system-out>
trace_id=4d2c3b2e, env=staging
</system-out>
</testcase>
</testsuite>
Mapping failure reasons to request/step
Treat the failure “type” and message as a contract. A good rule is:
- Put the classification in
type(or at least at the start ofmessage). - Put the human-readable reason in
message. - Put the minimum reproduction context inside the failure body.
Suggested taxonomy that works well for API regression in CI:
timeout: request exceeded a timeout budgetnetwork: DNS failure, connection refused, TLS errorauth: 401/403, missing token, invalid signatureassertion: contract mismatch (status, headers, JSONPath)
If you already model steps in YAML, you have the perfect stable key to attach this to: the step name.
GitHub Actions: publish the report, keep artifacts, preserve exit codes
There are three distinct outputs you usually want:
- Correct job status (pass/fail) via exit code
- Human-friendly UI in GitHub (check run + annotations)
- Debuggable artifacts (JUnit, logs, optional JSON)
The one gotcha is that if your test step exits non-zero, subsequent steps do not run unless you explicitly allow it. So you need a pattern that:
- captures the exit code
- continues the workflow to upload artifacts and publish the report
- fails the job at the end if needed
GitHub Actions workflow (JUnit + artifacts + final failure)
This example assumes your repository has a script that runs the tests and writes reports/junit.xml (DevTools CLI can output JUnit, see the Newman alternative for CI guide).
name: api-tests
on:
pull_request:
jobs:
api:
runs-on: ubuntu-24.04
steps:
- uses: actions/checkout@v4
- name: Run API tests (write JUnit to reports/junit.xml)
id: run
shell: bash
run: |
set +e
./ci/run-api-tests
code=$?
echo "exit_code=$code" >> "$GITHUB_OUTPUT"
exit 0
- name: Upload reports as artifacts
if: always()
uses: actions/upload-artifact@v4
with:
name: api-test-reports
path: reports/
retention-days: 7
- name: Publish JUnit report to GitHub (check run + annotations)
if: always()
uses: dorny/test-reporter@v1
with:
name: API Tests
path: reports/junit.xml
reporter: java-junit
fail-on-error: false
- name: Fail job if tests failed
if: ${{ steps.run.outputs.exit_code != '0' }}
run: exit 1
What this buys you:
- Your test runner can fail normally.
- You still get JUnit upload and a rendered report.
- The job status is correct at the end.
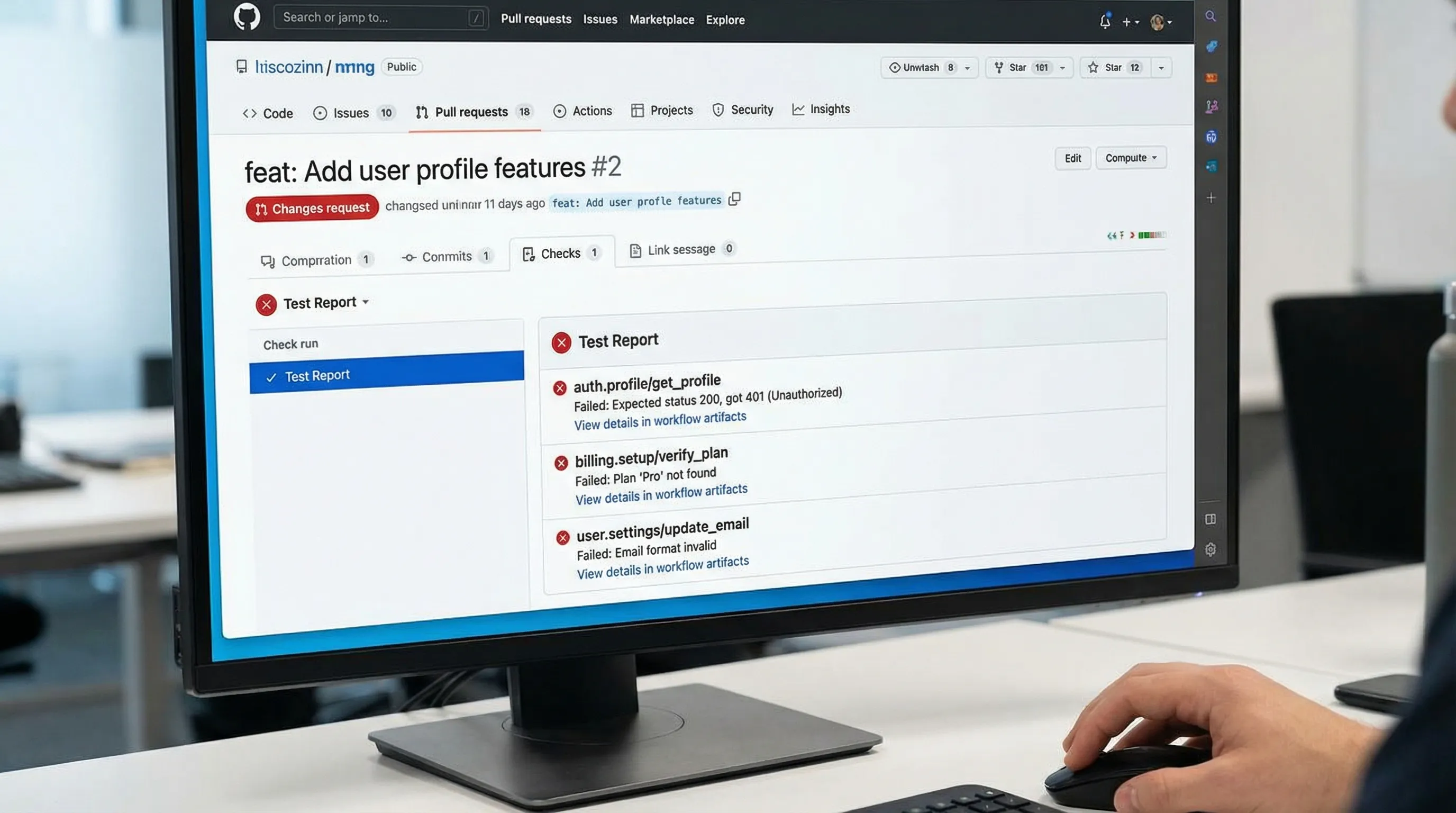
Artifacts vs annotations (use both, but for different purposes)
Artifacts are for deep debugging and auditability.
Store:
reports/junit.xml(what the UI consumes)- runner logs (stdout/stderr)
- optional machine-readable report (JSON) if you have one
Artifacts are durable, download-friendly, and do not spam PRs. They are also the right place for sensitive-ish data, as long as you control retention and content (redact tokens, avoid raw response bodies unless absolutely necessary).
Annotations are for fast review and routing.
Annotations (created via a check run publisher like dorny/test-reporter, or via workflow commands) are what make failures feel “native” in GitHub. They are great when:
- the failure message is short
- the test name maps to a file/step a developer can fix
They are not great for:
- full request/response dumps
- noisy failures across hundreds of steps
- anything that will hit platform limits (GitHub caps annotation volume per check run)
A good compromise is: annotate the step name and reason, keep the raw material in artifacts.
Exit codes and failure reasons you should standardize
GitHub Actions only understands success (0) and failure (non-zero). Your runner should still expose why it failed, and JUnit is the most portable place to put it.
Practical mapping
- Assertions failed (contract mismatch): exit code non-zero, JUnit
<failure type="assertion"> - Timeout: exit code non-zero, JUnit
<failure type="timeout"> - Auth: exit code non-zero, JUnit
<failure type="auth"> - Network/TLS: exit code non-zero, JUnit
<error type="network">or<failure type="network">
A subtle but useful distinction:
- Use
failurewhen the test ran and concluded “wrong behavior”. - Use
errorwhen the test could not be evaluated (infra, network, runner crash).
If you later decide to implement retry logic, this separation helps you avoid retrying “real failures” (assertions) while still retrying transient errors.
Why this is harder in Postman/Newman and Bruno
Newman can output JUnit, but the mapping tends to be coupled to collection structure and iteration naming, and those often drift from how teams review changes in Git. Postman also encourages UI-driven editing, which means test identity can change without obvious diffs.
Bruno is closer to Git-first, but it still uses its own file format rather than native YAML, so you often end up translating concepts (and identity) between tools.
With DevTools, the flow definition is native YAML, which means:
- step names can be kept stable across PRs
- diffs show exactly what changed
- JUnit testcase names can match what reviewers see in the YAML
A real-world workflow: chaining state, reporting failures, keeping PRs readable
A typical regression flow does request chaining (login, create resource, verify, cleanup). When a middle step fails, the value is not “test failed”, it is “step X failed, and X is the step that produced token/id Y”.
If you encode each step as its own testcase, the report will naturally tell you:
- where the chain broke
- whether it was state/auth (401, missing token)
- whether it was a contract assertion
This same pattern applies beyond internal services. For example, if you are validating integrations with third-party APIs or services that operate across regions, you want failures labeled by the exact step that talks to that system. A team testing a geo-targeted posting pipeline for a service like TokPortal's TikTok distribution workflow would benefit from seeing "UploadVideo" fail with auth versus "Publish" fail with timeout, without reading raw logs.
Frequently Asked Questions
Do I need JUnit if I already have logs? Logs are necessary, but they are not a UI. JUnit gives you structured failures that GitHub can display, filter, and annotate, while logs remain an artifact for deep debugging.
Should I create one JUnit testcase per flow or per request step? For API workflows, per step is usually more actionable. It localizes failures to a specific request node and keeps chained failures obvious.
How do I avoid flaky test reports when steps are parallelized? Keep testcase names stable (step names), avoid including volatile data (timestamps, UUIDs) in failure messages, and ensure each parallel shard writes a separate JUnit file that you merge or publish as multiple paths.
What should go into the failure message vs artifacts? Put the classification and the minimal human hint in the JUnit failure message (auth/timeout/assertion/network plus a short reason). Put full logs, optional JSON reports, and any safe debug context into artifacts.
How do I make sure artifacts still upload when tests fail? Use if: always() on upload and report publishing steps, and capture the test step’s exit code so the job can fail at the end.
Put your YAML flows in Git, then make CI reports match them
If your API tests are still tied to Postman UI state, or JUnit output names that do not correspond to anything in Git, start by fixing identity: stable step names in a YAML flow.
DevTools is designed around that workflow, record traffic, export native YAML, review changes in PRs, and run locally or in CI with JUnit output. Start with the CI setup in the Newman alternative guide and keep your reports as readable as your flows.
This post is part of the API Testing in CI/CD guide — the complete resource for moving API tests from manual tools into automated pipelines.