 Star on GitHub
Star on GitHub
From Manual to Automated: Migrating Your Postman Collections to CI-Ready API Tests
Postman was never designed to be your source of truth for regression. It is a great interactive client, but once collections become “the test suite”, you inherit UI-locked diffs, brittle scripting, and CI glue code that is harder to review than the API changes it is meant to catch.
Postman’s pricing shifts in 2026 pushed a lot of teams to finally pay down that debt. If you are feeling that pain, the goal is not “find another GUI”, it is to migrate Postman to automated API testing that behaves like the rest of your engineering system: deterministic inputs, reviewable changes, Git history, and CI-native execution.
This tutorial walks through a migration that turns Postman collections into CI-ready YAML API tests using DevTools (free, open-source, YAML-first). You will export collections and environments, convert them into readable YAML flows, handle request chaining and variable extraction, manage secrets correctly, and wire everything into a pipeline that fails fast with actionable reports.
What you are migrating (and what you should not)
Before you touch any tools, separate Postman into what is worth migrating vs what is accidental complexity.
The artifacts you likely have today
- Collections with folders representing features or services
- Environments (base URLs, tokens, tenant IDs)
- Globals (usually a smell)
- Pre-request scripts (auth bootstrapping, timestamps, signing)
- Tests (status checks, JSON assertions, schema checks)
- Newman runs in CI, often with hand-rolled reporters
The target state
- YAML flows stored in Git (diffable, code-reviewed, code-owned)
- Request chaining based on extracted values (IDs, tokens, CSRF)
- Environment config that is explicit, templated, and injected in CI
- Secrets handled by your CI secret store (not exported JSON)
- Deterministic assertions that reduce flaky failures
Here is a practical mapping that helps when you start converting.
| Postman concept | Typical usage in teams | YAML-first replacement (DevTools style) | Migration note |
|---|---|---|---|
| Collection folders | Organize related requests | Flow files / directories | Preserve structure in repo layout |
| Environment variables | baseUrl, token, tenant | CI env vars or env templates | Keep secrets out of Git |
| Pre-request scripts | Set headers, compute auth | Explicit steps + captures + small JS nodes | Avoid “ambient state” |
| Tests (pm.test) | Assertions, schema checks | YAML assertions + optional JS validations | Prefer invariant checks |
| Newman CLI | Run in CI, produce JUnit | DevTools CLI runner in CI | Pin versions for determinism |
If your collection is 50 percent “pre-request script frameworks”, treat that as an engineering smell. You can migrate it, but you should first decide whether those scripts encode real product behavior or just paper over tool limitations.
Postman, Newman, Bruno: what changes in practice
If you are coming from Postman/Newman, you are usually dealing with two sources of friction:
- Format lock-in: collections are JSON exports optimized for the Postman app, not for Git review.
- CI ergonomics: Newman is a runner for Postman artifacts, so you inherit Postman’s variable model, scripting, and export churn.
Bruno improves the “tests in Git” story compared to Postman, but it still uses its own file format and relies heavily on scripting for anything beyond basic assertions. That is not wrong, but it means portability and reviewability depend on a tool-specific DSL and runtime.
DevTools’ key difference for migrations is that the output is native YAML that you can review like code, and that you can run locally or in CI with a CLI designed for test execution.
Step 0: Decide your migration strategy (export vs record)
There are two reliable ways to migrate Postman-based testing into YAML flows.
Strategy A: Export collections and environments
Use this when:
- Your collections already represent stable API workflows.
- Requests are mostly direct API calls (not browser noise).
- The collection is your real test asset.
Strategy B: Record real traffic (HAR) and convert
Use this when:
- The “real workflow” is better represented by a web or mobile client.
- Postman collections have drifted away from production behavior.
- You want to capture auth, CSRF, and headers exactly once, then normalize.
DevTools supports converting real browser traffic into YAML flows, which is often the fastest path to correct request chaining. If you have complex session behavior, consider reading the DevTools post on a repeatable Chrome DevTools Network to YAML flow pipeline.
This tutorial focuses on Strategy A because it matches “migrating your Postman collections”, but you can mix both: export what is good, record what is unclear.
Step 1: Inventory your collections like a test suite, not like a workspace
The most expensive migrations are the ones that try to “convert everything” without deciding what should exist in CI.
Create a short inventory document (in your repo or ticket system) with three columns:
- Workflow name (what business capability it validates)
- Where it runs today (manual only, scheduled monitor, Newman in CI)
- What it blocks (PR merge, deploy gate, or just a signal)
Then classify each collection folder:
- Smoke: fast, deterministic, blocks PRs
- Regression: broader, runs on merge or nightly
- Exploratory: stays manual (Postman can still exist here)
Treat this as test architecture. Your goal is not to preserve Postman’s structure, it is to preserve confidence.
Step 2: Export Postman collections (v2.1) cleanly
For migration work, you want stable exports.
Export the collection
In Postman:
- Open the collection
- Export
- Choose Collection v2.1
- Save it into a temporary directory (do not commit it yet)
If you have multiple collections, export each to a file with a predictable name, for example:
billing.postman_collection.jsonauth.postman_collection.json
Export environments
Export the environments you run against (staging, dev, prod-like).
Be strict here:
- Do not export real secrets into files that will land in Git.
- If Postman has secrets in environment variables today, rotate them as part of the migration. Assume they leaked.
A safe pattern is to export environments, immediately redact them, and commit only templates (more on that later).
Normalize the JSON for diffability (optional but recommended)
Even if you do not commit the exports, normalizing the JSON reduces churn while you iterate.
Use a formatter like jq to stable-print the JSON:
jq -S . billing.postman_collection.json > billing.postman_collection.sorted.json
This is not about long-term storage, it is about making conversion steps reproducible.
Step 3: Create a repo layout that supports Git review and CI
You are migrating into “tests as code”, so create a structure that makes reviews and ownership easy.
A pragmatic layout:
api-tests/
flows/
smoke/
regression/
env/
local.env.example
ci.env.example
staging.env.example
scripts/
redact-postman-export.sh
.github/workflows/
api-smoke.yml
api-regression.yml
Keep flows small and composable. When everything is one giant flow, a single failure produces useless logs and serial execution slows down CI.
If you want more detail on keeping YAML diffs readable, DevTools has a focused guide on YAML API test file structure conventions.
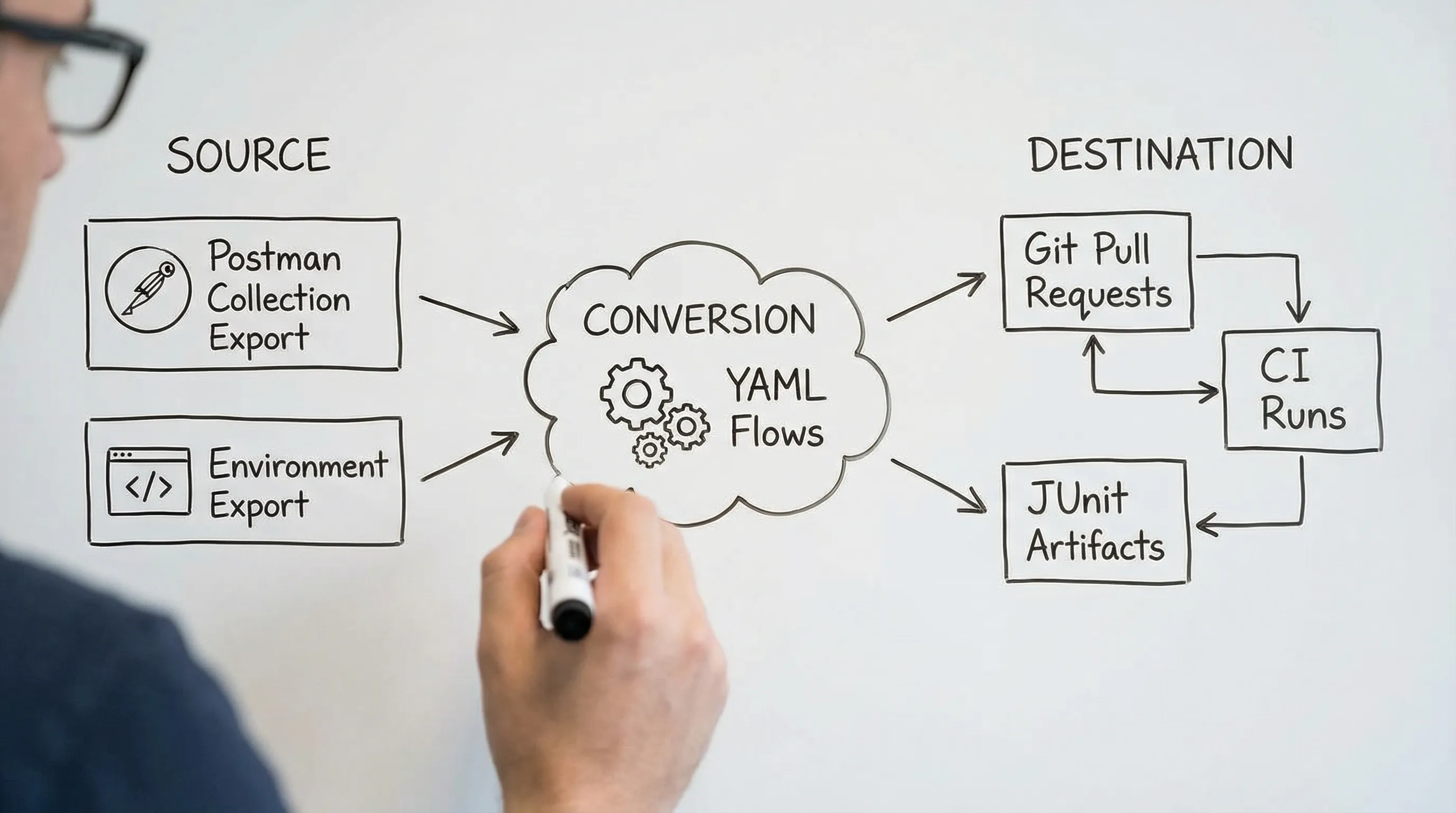
Step 4: Convert a single “golden path” folder first
Do not start by converting the entire suite. Pick one workflow that is:
- high value
- stable
- representative (auth + a resource lifecycle)
You want an early win that exercises chaining, assertions, and secrets.
Choose what “CI-ready” means for this workflow
Define it precisely:
- No manual steps
- No shared mutable state across test runs
- No reliance on “already logged in” UI state
- Assertions check invariants, not volatile fields
- The flow can run in parallel with itself (or at least not corrupt others)
If your team cannot agree on these properties, you will end up re-implementing Postman pain in a new format.
Step 5: Translate requests into YAML steps
A Postman request becomes a YAML step with:
- method
- URL (built from a base URL + path)
- headers
- body
- assertions
- captures (values to reuse)
Example: Postman request
A common Postman pattern looks like:
- URL:
{{baseUrl}}/v1/projects - Header:
Authorization: Bearer {{token}} - Test script:
pm.test("201 created", () => pm.response.to.have.status(201));
pm.test("has id", () => {
const json = pm.response.json();
pm.expect(json.id).to.be.a("string");
});
The same intent as a YAML-first step
Below is a representative YAML flow pattern (focus on the shape, not the exact runner keys if your org standard differs). The important part is that it is readable and reviewable.
workspace_name: Projects Create and Verify
env:
BASE_URL: '{{#env:BASE_URL}}'
API_TOKEN: '{{#env:API_TOKEN}}'
RUN_ID: '{{#env:RUN_ID}}'
run:
- flow: ProjectsCreateAndVerify
flows:
- name: ProjectsCreateAndVerify
steps:
- request:
name: CreateProject
method: POST
url: '{{BASE_URL}}/v1/projects'
headers:
Authorization: 'Bearer {{API_TOKEN}}'
Content-Type: application/json
body:
name: 'ci-{{RUN_ID}}'
- js:
name: ValidateCreate
code: |
export default function(ctx) {
if (ctx.CreateProject?.response?.status !== 201) throw new Error("Expected 201");
if (typeof ctx.CreateProject?.response?.body?.id !== "string") throw new Error("id must be a string");
}
depends_on: CreateProject
- request:
name: GetProject
method: GET
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Authorization: 'Bearer {{API_TOKEN}}'
depends_on: CreateProject
- js:
name: ValidateGet
code: |
export default function(ctx) {
if (ctx.GetProject?.response?.status !== 200) throw new Error("Expected 200");
if (ctx.GetProject?.response?.body?.id !== ctx.CreateProject?.response?.body?.id) throw new Error("ID mismatch");
if (ctx.GetProject?.response?.body?.name !== `ci-${ctx.RUN_ID}`) throw new Error("Name mismatch");
}
depends_on: GetProject
What changed compared to Postman:
- The test is data flow driven. You reference
{{CreateProject.response.body.id}}directly in later steps. - Variables are explicit (
env:block with{{#env:}}references), not implicit globals. - Assertions use
js:nodes that throw on failure, keeping validation logic visible and reviewable.
Common translation rules
Headers
Postman often includes browser-ish headers and “helpful defaults”. In CI, these become noise.
Prefer to keep:
- auth headers
- content-type / accept
- idempotency keys (if you use them)
Prefer to drop:
- user-agent and client hints
- accept-language
- cache-control (unless you are testing caching)
This is one of the fastest ways to reduce flaky failures caused by inconsistent header sets.
Bodies
If Postman stores a raw JSON string, convert it into YAML maps for readability, unless the API requires exact text formatting.
If you need to keep exact JSON for signature reasons, use YAML block scalars:
body: |
{"name":"ci-{{RUN_ID}}","flags":{"a":true}}
Step 6: Convert Postman variable models into deterministic inputs
Postman has several variable scopes. Migrating becomes much easier when you collapse them into a simpler model.
Recommended variable layers for CI
Use three layers:
- Committed templates:
env/*.env.example - Developer local overrides:
.env(gitignored) - CI secrets and variables: GitHub Actions secrets, GitLab CI variables, etc.
A committed template might look like:
# env/ci.env.example
BASE_URL=https://api.staging.example.com
API_TOKEN=
RUN_ID=
Then in CI you set API_TOKEN as a secret, and RUN_ID as a generated value.
Replace Postman globals with run-scoped IDs
A classic Postman anti-pattern is “global projectId” that lingers between runs.
In YAML flows, prefer run-scoped captures:
- Create resource
- Capture ID
- Use ID
- Delete resource (optional teardown)
This makes parallelism possible later.
Use a run identifier
If your workflow creates server-side objects, add a RUN_ID string to names, emails, or idempotency keys.
Generate it in CI as ${GITHUB_RUN_ID} or a short SHA. For local runs, generate it in a wrapper script.
Step 7: Convert chaining and extraction (the part Newman never made pleasant)
Chaining is where most Postman suites hide state in scripts.
Reference values from earlier responses
You already saw referencing {{CreateProject.response.body.id}}. In DevTools, there is no separate capture: block. You reference node outputs directly using {{NodeName.response.body.field}} syntax.
Here is a slightly more realistic pattern with nested data and arrays:
steps:
- request:
name: GetUser
method: GET
url: '{{BASE_URL}}/v1/users/me'
headers:
Authorization: 'Bearer {{API_TOKEN}}'
- request:
name: GetRoleDetails
method: GET
url: '{{BASE_URL}}/v1/users/{{GetUser.response.body.user.id}}/roles/{{GetUser.response.body.user.roles.0}}'
headers:
Authorization: 'Bearer {{API_TOKEN}}'
depends_on: GetUser
Avoid implicit coupling
If a step needs a value, make it obvious by using clear node names and depends_on to declare ordering.
A migration tip: if your Postman suite uses pm.collectionVariables.set("x", ...) all over the place, you likely have hidden coupling. Convert those into direct {{NodeName.response.body.field}} references, or your YAML will become the same "spooky action at a distance", just in a different file.
Step 8: Translate Postman test scripts into YAML assertions
Postman tests are JavaScript, which means teams often end up writing mini frameworks. That is flexible, but it is also why reviews become unproductive.
Map the 80 percent case to js validation nodes
Most suites check:
- status codes
- presence/type of fields
- equality against values from earlier responses
- simple header checks
In DevTools, assertions are js: nodes that throw new Error() on failure. Your goal is the same: assert invariants that survive harmless response evolution.
A practical pattern:
steps:
- request:
name: GetProject
method: GET
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Authorization: 'Bearer {{API_TOKEN}}'
depends_on: CreateProject
- js:
name: ValidateGetProject
code: |
export default function(ctx) {
const res = ctx.GetProject?.response;
if (res?.status !== 200) throw new Error("Expected 200");
if (res?.headers?.["content-type"]?.indexOf("application/json") === -1) throw new Error("Expected JSON");
if (res?.body?.id !== ctx.CreateProject?.response?.body?.id) throw new Error("ID mismatch");
if (!/^\d{4}-\d{2}-\d{2}T/.test(res?.body?.createdAt)) throw new Error("Timestamp format invalid");
}
depends_on: GetProject
When to add more JavaScript
Some assertions require more logic:
- canonicalizing arrays before comparing
- validating signatures
- computing derived values
Keep JS nodes small and deterministic. Prefer them for validation and normalization rather than for controlling the entire test flow.
A reasonable split is:
- YAML
request:nodes for the request/response surface js:nodes for validation, extraction, and producing derived values
If you want a deeper set of patterns, DevTools has a practical guide on JSON assertion patterns for API tests.
Step 9: Handle environments, secrets, and auth without leaking data
Postman makes it easy to accidentally commit secrets because the UX encourages storing everything in environments.
Your migration is a chance to fix this properly.
Rule: secrets never live in YAML
YAML flows should reference environment variables.
Good:
headers:
Authorization: 'Bearer {{API_TOKEN}}'
Bad:
headers:
Authorization: 'Bearer eyJhbGciOi...'
Secrets in CI
In GitHub Actions:
- Store
API_TOKENin GitHub Secrets - Inject it via
env:
In GitLab:
- Use masked CI variables
If your auth requires exchanging credentials for a token, prefer to do the exchange as part of the flow, and keep the input secret minimal (client secret, private key).
Auth patterns that migrate cleanly
Login then reuse token
workspace_name: Login and List Projects
env:
BASE_URL: '{{#env:BASE_URL}}'
TEST_USER_EMAIL: '{{#env:TEST_USER_EMAIL}}'
TEST_USER_PASSWORD: '{{#env:TEST_USER_PASSWORD}}'
run:
- flow: LoginAndList
flows:
- name: LoginAndList
steps:
- request:
name: Login
method: POST
url: '{{BASE_URL}}/v1/login'
headers:
Content-Type: application/json
body:
email: '{{TEST_USER_EMAIL}}'
password: '{{TEST_USER_PASSWORD}}'
- js:
name: ValidateLogin
code: |
export default function(ctx) {
if (ctx.Login?.response?.status !== 200) throw new Error("Login failed");
if (!ctx.Login?.response?.body?.token) throw new Error("No token returned");
}
depends_on: Login
- request:
name: ListProjects
method: GET
url: '{{BASE_URL}}/v1/projects'
headers:
Authorization: 'Bearer {{Login.response.body.token}}'
depends_on: Login
- js:
name: ValidateList
code: |
export default function(ctx) {
if (ctx.ListProjects?.response?.status !== 200) throw new Error("Expected 200");
}
depends_on: ListProjects
OAuth client credentials
Same structure, different endpoint. Reference the access token from the auth response via {{AuthRequest.response.body.access_token}}.
CSRF tokens
Capture CSRF from a response header or cookie, then pass it explicitly. Avoid “cookie jar magic” unless you are intentionally testing browser semantics.
Step 10: Make the YAML deterministic (so CI failures mean something)
Your Postman suite may “work on my machine” because you ran it slowly, manually, or against a stable dataset.
CI forces truth.
Common flake sources after migration
- Dynamic timestamps and UUIDs compared as exact values
- Pagination order that is not guaranteed
- Race conditions from parallel test runs creating the same resource
- Rate limits hit by concurrency
- Tests that assume pre-existing fixtures
Determinism tactics that scale
Use invariant assertions:
- check field presence, type, and allowed ranges
- check relationships between fields
- check that returned IDs match captured IDs
Control state:
- create unique resources per run
- cleanup if your environment cannot be reset
- avoid relying on shared tenants with other CI jobs
Reduce noise:
- strip irrelevant headers from requests
- assert only stable response headers
If you have a suite that constantly flakes, do not paper over it with retries. Fix the assertion model first. DevTools has a focused post on deterministic API assertions to stop flaky JSON tests in CI.
Step 11: Replace Newman with a CI-native runner
At this point you have YAML flows. Now you need two things:
- a repeatable install of the runner
- a consistent invocation that emits machine-readable output
DevTools provides a CLI designed to run YAML flows locally and in CI. Use it as your Newman replacement.
A good practice is to wrap the CLI in a script that:
- prints runner version
- sets default timeouts
- outputs JUnit and logs to a known directory
- returns a non-zero exit code on failure
Keep the wrapper boring. Your CI should not need to understand Postman exports or Newman reporters.
If you are specifically migrating Newman CI jobs, the DevTools guide on a Newman alternative for CI is worth skimming, mainly for runner and reporting expectations.
Step 12: Wire up GitHub Actions (copy-paste baseline)
A CI pipeline for API tests should do two things well:
- run the right subset at the right time
- preserve artifacts that make failures debuggable
Smoke tests on pull requests
Below is a baseline workflow structure. Adjust the installation step to match how your org pins binaries (checksum verification, internal mirror, etc.).
name: api-smoke
on:
pull_request:
jobs:
smoke:
runs-on: ubuntu-24.04
env:
BASE_URL: ${{ vars.STAGING_BASE_URL }}
API_TOKEN: ${{ secrets.STAGING_API_TOKEN }}
RUN_ID: ${{ github.run_id }}
steps:
- uses: actions/checkout@v4
- name: Install DevTools CLI
run: |
# Install pinned runner version here (org-specific)
echo "Install dev.tools runner"
- name: Run smoke flows
run: |
mkdir -p artifacts
# Example shape, replace with your actual runner command
# devtools run api-tests/flows/smoke --junit artifacts/junit.xml --log artifacts/run.log
- name: Upload artifacts
if: always()
uses: actions/upload-artifact@v4
with:
name: api-smoke-artifacts
path: artifacts
Key points that keep this maintainable:
- Use
if: always()for artifact uploads, so failures are diagnosable. - Use repo variables for non-secret config (like base URL).
- Use secrets only for tokens/credentials.
- Pin runner versions to avoid “CI changed under our feet” failures.
For a more production-ready setup with JUnit integration and parallel runs, DevTools has a dedicated guide for API regression testing in GitHub Actions.
Regression tests on merge and nightly
Add a second workflow that runs on pushes to main, and optionally a scheduled run.
You can also split by directory:
flows/smokeon PRflows/regressionon merge/nightly
That gives you fast feedback and deeper coverage without blocking every PR on the world.
Step 13: Add parallelism safely (once tests are deterministic)
Parallelism is the point where Postman plus Newman setups often collapse. YAML-first flows make it simpler because you can shard by file path.
A safe approach:
- Ensure each flow is self-contained (creates its own data)
- Shard by file glob or directory
- Control concurrency if you have rate limits
In GitHub Actions, matrix jobs can shard suites. Keep the sharding rules stable so you get consistent run time and consistent blame for failures.
If you are not ready for sharding, do not force it. Fix determinism first.
Step 14: Convert remaining collections systematically
Once your golden path is working end to end (local plus CI), convert the rest in batches.
A practical conversion rhythm:
- Convert one Postman folder into one YAML flow file
- Commit it in a PR with a clear scope
- Require review from API owners
- Run smoke suite on PR
- Merge, then watch regression suite behavior
Avoid a single mega-PR that converts everything. Reviewers cannot meaningfully validate 2,000 lines of test conversion plus production changes.
Step 15: Handle the hard cases (script-heavy Postman collections)
Some collections are effectively a custom test runner inside Postman.
Case: computed signatures (HMAC, AWS SigV4)
Do not try to replicate Postman’s “pre-request script library” pattern.
Instead:
- isolate signing to a small deterministic function (JS node or external helper)
- pass inputs explicitly
- assert that signing output is used, not that it matches a hardcoded value
Case: polling loops
If you have Postman scripts that loop until a job finishes, represent this explicitly with loop or retry constructs supported by your runner, and add time budgets.
A deterministic polling pattern asserts:
- the job eventually reaches a terminal state
- the time budget is reasonable nRather than sleeping for arbitrary durations.
Case: dynamic environments
If your Postman suite switches between multiple base URLs or tenants in one run, consider splitting it:
- one suite per environment
- environment selection is a CI concern (matrix), not a test concern
This reduces branching logic inside tests.
Step 16: Decommission Postman in CI without losing manual workflows
The migration does not require you to delete Postman.
A sane end state for many teams is:
- Postman stays for ad hoc calls and exploratory debugging
- YAML flows are the regression and smoke source of truth
- CI gates on YAML runs, not on Newman
Once CI confidence is stable:
- remove Newman jobs
- remove the need to export collections for CI
- keep Postman exports out of the critical path
This is where the pricing pressure stops being a fire drill and becomes an improvement.
Step 17: Make the suite reviewable and governable
The difference between “tests in Git” and “tests that help” is governance.
Require ownership
Add CODEOWNERS for api-tests/flows/** so changes get reviewed by service owners.
Keep PR diffs small and meaningful
YAML makes diffs readable only if you keep formatting stable. Pick conventions and enforce them (editorconfig, YAML linting, avoid re-serializing files with different key orders).
Store the right artifacts
In CI, store:
- JUnit XML
- runner logs
- minimal response context (redacted)
Do not store full response dumps by default if they may contain PII.
Step 18: Communicate the change (yes, this matters)
Most Postman migrations fail socially, not technically. Teams are used to clicking “Send” and seeing green checks in a UI.
Set expectations:
- YAML flows are the test source of truth
- PR review applies to tests
- flaky tests get fixed, not retried forever
If you are also tracking community sentiment about Postman pricing changes and migration approaches, a tool like Redditor AI can surface relevant Reddit threads quickly so you can learn from other teams’ pain points and workarounds.
Practical migration checklist (use this to drive the work)
Use this as a cutover gate for each collection batch:
- YAML flows exist under
api-tests/flows/... - No secrets committed, all sensitive values come from CI secrets
- Each flow can run from a clean environment without manual priming
- Chaining is explicit (captures and references), no hidden global state
- Assertions focus on invariants (types, relationships, allowed ranges)
- CI runs on PR (smoke) and on merge/nightly (regression)
- JUnit and logs are uploaded on failure
- Newman jobs removed for the migrated scope
Where DevTools fits (and where it does not)
DevTools is a good fit when you want:
- YAML-first tests stored in Git
- multi-step API workflows with request chaining
- local-first execution and CI runs
- a path from real traffic (HAR) to executable tests
It is not a magic converter that will preserve every Postman scripting trick. That is a feature, not a limitation. A migration is the moment to delete accidental complexity and encode only what should block a deploy.
If you want the closest DevTools-specific walkthrough for import and conversion details, the canonical starting point is the DevTools guide on migrating from Postman. Use it alongside this tutorial: the guide helps with tool-specific steps, and this article helps you design the migration so it results in a CI-native suite.