 Star on GitHub
Star on GitHub
Deterministic API Assertions: Stop Flaky JSON Tests in CI
Flaky JSON assertions are rarely “random”. They are deterministic failures caused by non-deterministic data (timestamps, UUIDs, ordering, floating point, pagination drift) meeting overly strict comparisons (full-body equals, snapshot diffs without normalization) inside a CI environment that amplifies timing and concurrency.
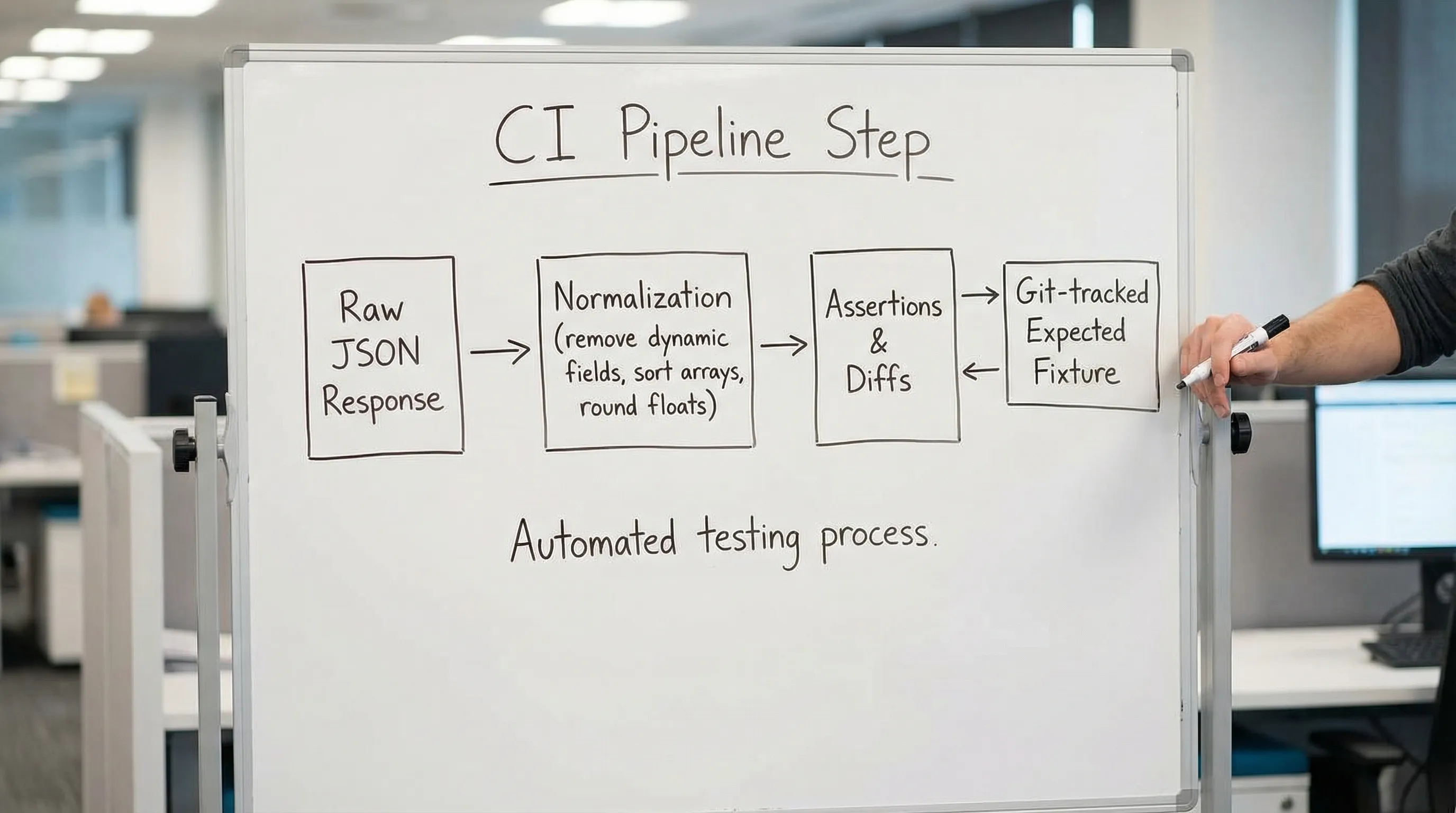
If you want CI runs you can trust, you need a deterministic assertion strategy: assert invariants, normalize what is inherently unstable, and keep those rules reviewable in Git.
YAML-first workflows (like DevTools flows) are a good fit here because your request definitions, JS validation nodes, and normalization decisions are plain text. Reviewers can see exactly what changed in a pull request, instead of spelunking through UI state (Postman) or scattering logic across disconnected scripts (Newman, Bruno).
What “deterministic API assertions” actually means
Deterministic does not mean “assert everything”. It means:
- Same code + same environment = same pass/fail result.
- Failures correspond to real regressions (contract breaks, logic bugs, incompatible changes), not incidental variance.
In practice, that means you should treat JSON responses as a mix of:
- Stable contract: required fields, types, allowed ranges, enums, structural shape, invariants.
- Expected variability: server-generated IDs, timestamps, ordering, computed floats, paging cursors, trace IDs.
The biggest anti-pattern in CI is a full JSON equality assertion on a response that contains any expected variability.
The five sources of flaky JSON tests (and the deterministic fixes)
| Flake source | Typical symptom in CI | Deterministic fix (high level) |
|---|---|---|
Time-based fields (createdAt, updatedAt), UUIDs, server IDs | Snapshot diffs every run | Assert format/type, reference and reuse via node outputs, or redact before comparison |
| Unordered arrays | Same elements, different order | Compare as sets, or sort canonically before asserting |
| Floating point | Off by 0.000001 on different machines/data | Use tolerances, ranges, or rounding rules |
| Pagination | Page boundaries shift, cursors expire, totals change | Seed data, constrain sort, compare stable projections, or walk pages deterministically |
| Secrets/PII in bodies and fixtures | Tests become unshareable, diffs expose data | Redact/mask consistently and enforce it |
The rest of this post is concrete patterns for each.
Pattern 1: Timestamps, UUIDs, and other server-generated values
Stop asserting exact values for createdAt and friends
If you assert exact timestamps, you are really testing “did this request execute at the same nanosecond as last time”, which is not a product requirement.
What you usually want instead:
- Field exists
- Field matches a format (often RFC 3339 / ISO 8601, see RFC 3339)
updatedAtis present when expected (or absent when it should be)- Sometimes:
updatedAtchanges after an update (but do not compare to wall-clock time, compare relative behavior)
UUIDs: validate shape, then reference
For UUIDs, exact equality across runs is nonsense. Validate the shape (or that it is a non-empty string), then reference the actual value from the response body and use it for subsequent requests.
For UUID structure, see RFC 4122.
YAML example: validate formats with JS nodes, chain via node outputs
Below is a YAML flow using the DevTools format. JS validation nodes check format invariants rather than exact values.
env:
BASE_URL: '{{BASE_URL}}'
GITHUB_RUN_ID: '{{GITHUB_RUN_ID}}'
steps:
- request:
name: CreateUser
method: POST
url: '{{BASE_URL}}/users'
headers:
Content-Type: application/json
body:
name: 'ci-{{GITHUB_RUN_ID}}'
- js:
name: ValidateCreate
code: |
export default function(ctx) {
const res = ctx.CreateUser?.response;
if (res?.status !== 201) throw new Error("Expected 201");
const id = res?.body?.id;
if (!/^[0-9a-fA-F-]{36}$/.test(id)) throw new Error("id not UUID format");
const ts = res?.body?.createdAt;
if (!/^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(\.\d+)?Z$/.test(ts)) {
throw new Error("createdAt not ISO format");
}
return { validated: true };
}
depends_on: CreateUser
- request:
name: GetUser
method: GET
url: '{{BASE_URL}}/users/{{CreateUser.response.body.id}}'
depends_on: CreateUser
- js:
name: ValidateGet
code: |
export default function(ctx) {
const res = ctx.GetUser?.response;
if (res?.status !== 200) throw new Error("Expected 200");
if (res?.body?.id !== ctx.CreateUser?.response?.body?.id) throw new Error("ID mismatch");
if (res?.body?.name !== 'ci-' + ctx.GITHUB_RUN_ID) throw new Error("Name mismatch");
return { validated: true };
}
depends_on: GetUser
Key idea: you validate format for timestamps/UUIDs in JS nodes, then chain requests using node output references like {{CreateUser.response.body.id}}.
When you do need time determinism
Sometimes you are testing time behavior (expiry, TTL, ordering by time). In those cases, “format only” is insufficient. Prefer these approaches:
- Control time at the system boundary: inject a clock in the service, use a fixed time in tests (best, but requires app support).
- Assert relative behavior: “token expires within 5 minutes” is still tricky, but you can assert server-provided
expiresInis within a range. - Avoid wall-clock comparisons in CI: CI runners can be under load; network jitter turns tight time windows into flakes.
Pattern 2: Unordered arrays (canonical sorting and set comparisons)
JSON arrays are ordered, but many APIs return arrays whose order is not contractually guaranteed unless you specify a sort. If you compare arrays by position, you are implicitly asserting a sort order.
Deterministic options:
Option A: Make the API deterministic
If the endpoint supports it, enforce ordering in the request:
?sort=createdAt&order=asc?orderBy=id
Then assert the order explicitly.
Option B: Compare as sets (project stable keys)
If the order is not meaningful, don’t assert order. Instead:
- Project each element to stable keys (often
idor(id, type)) - Compare sets (or compare sorted projections)
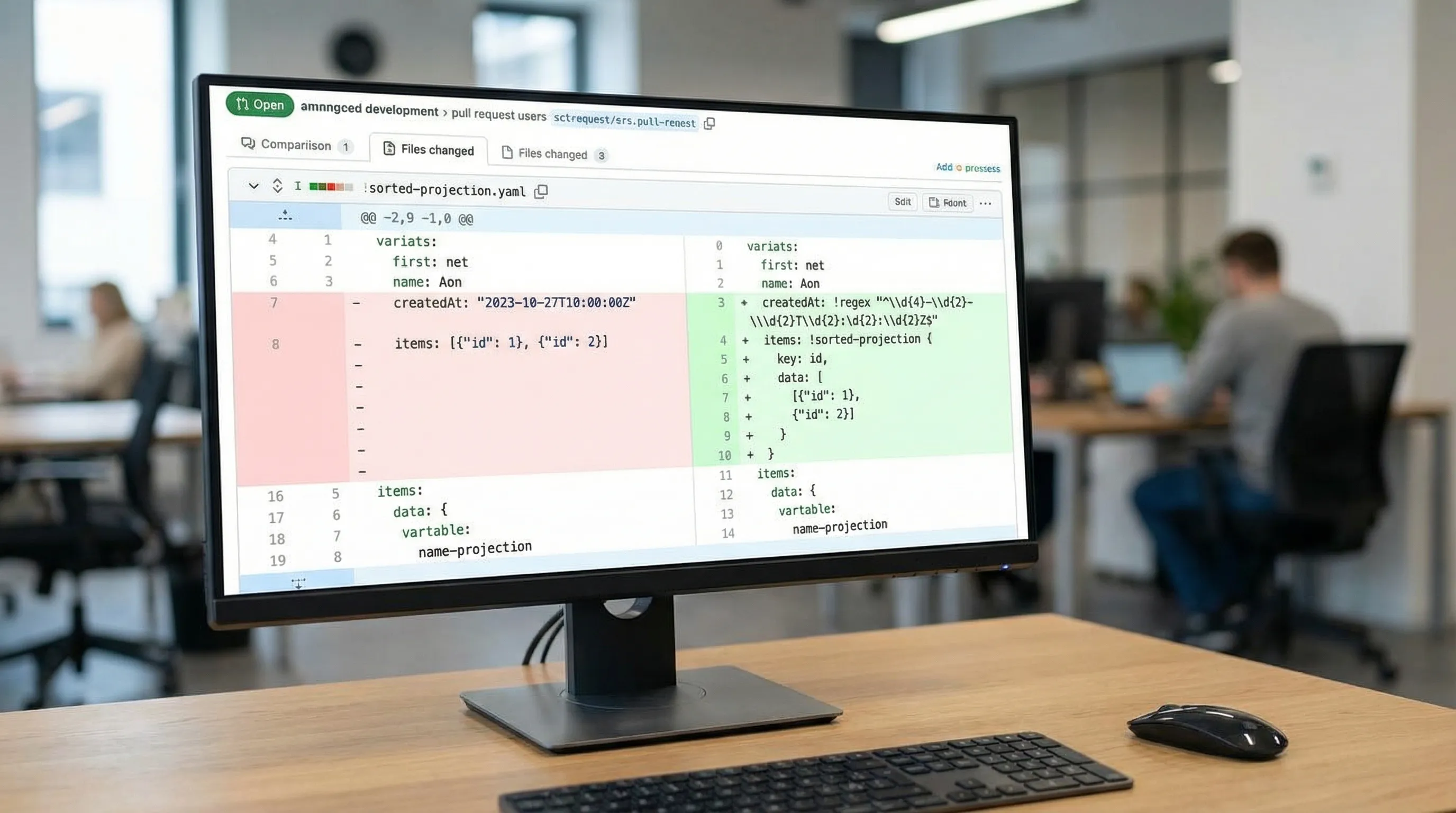
Option C: Canonically sort before snapshot comparisons
If you maintain expected JSON fixtures in Git, normalize responses before comparing them.
A practical approach in CI is to use jq to sort arrays by a stable key and sort object keys for stable diffs:
jq -S '.items |= sort_by(.id)' response.json > response.normalized.json
-S sorts object keys, which makes diffs stable even when serializers reorder fields. Array sorting is on you.
YAML example: normalize list responses by projection
steps:
- request:
name: ListUsers
method: GET
url: '{{BASE_URL}}/users'
query_params:
limit: '50'
sort: id
- js:
name: ValidateListUsers
code: |
export default function(ctx) {
const res = ctx.ListUsers?.response;
if (res?.status !== 200) throw new Error("Expected 200");
const items = res?.body?.items;
if (!Array.isArray(items)) throw new Error("items must be array");
for (const item of items) {
if (!/^[0-9a-fA-F-]{36}$/.test(item.id)) {
throw new Error("id not UUID: " + item.id);
}
if (!/^[^@]+@[^@]+\.[^@]+$/.test(item.email)) {
throw new Error("invalid email: " + item.email);
}
}
return { count: items.length };
}
depends_on: ListUsers
Notice what we did not do: assert the entire items array equals a stored snapshot.
Pattern 3: Floating point comparisons (tolerance rules)
Floating point output is a classic CI flake vector, especially when values are the result of aggregation, currency conversions, or anything that mixes integers and floats.
The anti-pattern:
$.total == 12.34
Better deterministic strategies:
Use tolerance (absolute or relative)
- Absolute tolerance:
abs(actual - expected) <= 0.01 - Relative tolerance:
abs(actual - expected) / expected <= 0.001
Choose one and document it. Don’t silently loosen assertions until CI passes.
Assert ranges, not exact values
If business logic allows it, prefer invariants:
- Total is non-negative
- Total increases when you add items
- Total equals sum of line items within tolerance
Round deterministically
If the API returns floats but the domain is currency, consider returning integers (cents) or decimal strings. If you cannot change the API, define rounding rules in your tests.
YAML example: tolerance check via JS node
steps:
- request:
name: GetInvoice
method: GET
url: '{{BASE_URL}}/invoices/{{invoiceId}}'
- js:
name: ValidateInvoiceTotal
code: |
export default function(ctx) {
const res = ctx.GetInvoice?.response;
if (res?.status !== 200) throw new Error("Expected 200");
const total = res?.body?.total;
const expected = 12.34;
const tolerance = 0.01;
if (Math.abs(total - expected) > tolerance) {
throw new Error("Total " + total + " not within " + tolerance + " of " + expected);
}
return { total };
}
depends_on: GetInvoice
JS validation nodes give you full control over tolerance logic. You can use absolute tolerance, relative tolerance, or rounding rules without being limited to a fixed matcher vocabulary.
Pattern 4: Pagination without unstable comparisons
Pagination flakes usually come from tests that assume a stable dataset boundary when none exists.
Common failure modes:
- New records inserted concurrently shift items between pages.
- Cursor tokens expire between page requests.
- Total counts change.
- Default ordering changes (or is undefined).
Deterministic strategies:
Constrain the dataset
For CI, you want a dataset you control:
- Seed fixtures in a dedicated test environment.
- Namespace test data with a run-scoped prefix (and clean it up).
- Filter queries to only include your test records.
Make ordering explicit
Always request an explicit, stable order. If you do not specify order, you are not allowed to assert page boundaries.
Compare stable projections across pages
Instead of snapshotting each page JSON:
- Walk pages, collect
items[*].id - Sort the collected IDs
- Assert against expected IDs (or expected count) for your filtered namespace
YAML example: stable pagination assertions
env:
GITHUB_RUN_ID: '{{GITHUB_RUN_ID}}'
steps:
- request:
name: Page1
method: GET
url: '{{BASE_URL}}/users'
query_params:
prefix: 'ci-{{GITHUB_RUN_ID}}'
limit: '20'
sort: id
- js:
name: ValidatePage1
code: |
export default function(ctx) {
const res = ctx.Page1?.response;
if (res?.status !== 200) throw new Error("Expected 200");
if (!Array.isArray(res?.body?.items)) throw new Error("items must be array");
return { cursor: res.body.nextCursor, ids: res.body.items.map(i => i.id) };
}
depends_on: Page1
- request:
name: Page2
method: GET
url: '{{BASE_URL}}/users'
query_params:
prefix: 'ci-{{GITHUB_RUN_ID}}'
limit: '20'
sort: id
cursor: '{{ValidatePage1.cursor}}'
depends_on: ValidatePage1
- js:
name: ValidatePage2
code: |
export default function(ctx) {
const res = ctx.Page2?.response;
if (res?.status !== 200) throw new Error("Expected 200");
const page2Ids = res?.body?.items?.map(i => i.id) || [];
const allIds = [...ctx.ValidatePage1.ids, ...page2Ids].sort();
return { allIds, totalCount: allIds.length };
}
depends_on: Page2
The JS nodes let you collect IDs across pages, sort them, and produce a stable set for comparison. This avoids relying on page-boundary stability.
Pattern 5: Redaction and masking as part of the assertion contract
Flakiness is not the only failure mode. Teams also end up weakening assertions because the “expected JSON” includes secrets or PII that cannot be committed to Git.
A deterministic workflow treats redaction as a first-class rule set:
- Define which fields must never be stored (tokens, cookies, API keys, session IDs).
- Decide whether fields are replaced with placeholders (
"<redacted>") or removed entirely. - Apply the same redaction rules to:
- Recorded traffic (HAR)
- Stored JSON fixtures
- CI logs and artifacts
If you record browser traffic to bootstrap flows, keep raw HAR files local and only commit sanitized outputs. DevTools has a practical guide on this approach: How to Redact HAR Files Safely.
Masking strategy: remove vs replace
Both can be deterministic, but they lead to different assertions:
| Strategy | Pros | Cons | Good for |
|---|---|---|---|
| Remove fields | Simplest diffs, avoids any accidental leakage | You cannot assert “field exists” | Tokens, cookies, transient IDs |
| Replace with placeholder | You can assert presence and structure | Requires consistent placeholder rules | Emails, names, addresses in fixtures |
A common compromise is:
- Remove authentication material entirely.
- Replace PII with stable fake values.
- Keep non-sensitive stable fields as-is.
Putting it together: deterministic JSON assertions in a Git workflow
A reliable CI setup has two layers:
Layer 1: YAML flows and assertions that only encode stable truth
This is where YAML-first shines. A pull request diff can show:
- Which fields you chose to assert exactly in JS validation nodes
- Which fields you chose to assert by format (regex checks)
- Where you reference and reuse IDs across steps (request chaining via node outputs)
- What you intentionally ignore (and why)
That is hard to review in Postman (UI state), and often hard to standardize in Newman (JS tests drift per author). Bruno is closer because it is text-based, but it still uses its own format and often pushes logic into scripts, which tends to recreate the same “hidden behavior” problem over time.
If you are migrating, DevTools documents a pragmatic path from Postman collections and scripts into reviewable YAML assertions: Migrate from Postman to DevTools.
Layer 2: A normalization step for snapshot-like comparisons (only when needed)
Snapshot diffs can be valuable, but only after you define a canonical form.
A canonicalization pipeline for JSON snapshots typically does:
- Delete time-based fields (
createdAt,updatedAt,timestamp) - Delete request/trace IDs (
requestId,traceId) - Sort arrays that are semantically sets
- Round floats to a defined precision
- Sort object keys
You can implement this with jq in CI, or via runner-native transforms if available.
Example: CI job that runs flows and stores normalized artifacts
If you run in GitHub Actions, keep the run auditable but sanitized. Store YAML in Git, upload logs and reports as artifacts, and redact consistently. See also: API regression testing in GitHub Actions and Auditable API Test Runs.
A practical checklist for eliminating flaky JSON tests
Use this as a review standard for PRs that modify API assertions.
For dynamic fields
- Assert format/type for timestamps and UUIDs, not exact values.
- Chain requests by referencing server-generated IDs via
{{NodeName.response.body.id}}. - Treat headers like
Date,Set-Cookie, and trace IDs as non-assertable unless you have a specific contract.
For arrays
- If order matters, make sort explicit in the request and assert order.
- If order does not matter, compare as a set (projection + sort).
For floats
- Never use strict equality on computed floats.
- Encode a tolerance or a rounding rule, and keep it consistent.
For pagination
- Filter to test-owned data.
- Specify stable sorting.
- Assert stable projections across pages, not full bodies.
For redaction
- Decide remove vs replace, then enforce it everywhere.
- Keep raw captures local; commit only sanitized YAML and fixtures.
Why YAML-first helps you stay deterministic over time
Determinism is not a one-time refactor. It is a maintenance discipline.
With YAML-based API testing stored in Git:
- Validation logic is visible in diffs (JS nodes inline with request steps).
- Reviewers can block "full JSON equals" regressions.
- Chaining rules are explicit (node output references next to their use).
- CI behavior is reproducible because the test definition is just code.
That is the core advantage over UI-locked collections (Postman) and script-heavy runners (Newman, Bruno): you can enforce deterministic conventions the same way you enforce code conventions.
If your current suite is noisy, start by changing only one thing: replace exact snapshot equality with format assertions + canonical sorting + tolerance rules where needed. CI will get quieter fast, and failures will start meaning something again.
Deterministic assertions matter even more in end-to-end API tests where flakiness in one step cascades through every downstream step. Getting assertions right at each point in the chain is what makes multi-step flows reliable in CI.