 Star on GitHub
Star on GitHub
API Tokens in CI: Scopes, Rotation, and Secret Hygiene
CI failures caused by auth are rarely “test failures”. They are usually identity failures: the runner used the wrong API tokens, with the wrong scopes, in the wrong environment, at the wrong time.
For experienced teams, the fix is not “store the token in a secret and move on”. You want a token model that is least-privilege, rotation-friendly, and hard to leak, while still being deterministic and reviewable in Git.
This guide focuses on API tokens in CI for YAML-based API testing (including chained, multi-request workflows), with concrete patterns you can review in pull requests and run locally or in CI.
The CI token baseline (what “good” looks like)
A CI token setup is healthy when it has these properties:
- Least privilege by default: scopes match the suite (smoke vs regression), not “admin so it passes”.
- Short lifetime when possible: mint per run (OIDC or auth flow) rather than long-lived static secrets.
- Explicit environment boundaries: staging token cannot touch prod, and vice versa.
- Rotation without downtime: you can rotate without breaking PR validation for a day.
- Non-leaky execution: tokens do not appear in logs, JUnit output, HAR artifacts, or PR comments.
- Reviewable changes: any auth-related change shows up as a readable Git diff.
YAML-first test definitions help here because the auth wiring is text you can diff. Compare that to Postman collections and environments where the auth config is split across UI state, exported JSON, and runner flags. Newman can run in CI, but teams often end up with token values living in exported environment files, or with hard-to-review script changes embedded in JSON.
Scopes: design them for test intent, not convenience
The fastest way to create flaky, risky CI is to give one token broad access and let every job use it.
Instead, model scopes around what the suite is allowed to prove.
Scope along three axes
API surface
- Smoke: minimal read and a single write path (often one create and one cleanup).
- Regression: full CRUD for a bounded resource set.
- Negative auth tests: dedicated “underprivileged” token to prove 403s.
Data domain
- Separate tokens for “tenant A” vs “tenant B” if your platform is multi-tenant.
- Separate tokens for “test data namespace” vs “shared staging data”.
Environment
- A staging token should be useless in prod even if leaked.
- Prefer separate auth clients per environment (separate OAuth clients, separate API key issuers, separate Vault paths).
Practical token roles that map cleanly to CI
| CI usage | Recommended token identity | Typical scopes (conceptual) | Notes |
|---|---|---|---|
| PR smoke gate | ci-smoke | read health, create minimal resource, delete that resource | Keep fast and low blast radius. |
| Nightly regression | ci-regression | broader CRUD within test namespace | Can be more privileged than smoke, still bounded. |
| Authz negative tests | ci-underprivileged | intentionally missing one permission | Prevents “we never assert 403” gaps. |
| Migration/seed jobs | ci-seed | limited admin for fixtures only | Separate from test runner tokens. |
The key is that these identities are stable concepts you can encode in CI environments and review in PRs.
Prefer “minted per run” tokens over stored static tokens
A stored static token is easy, but it is also:
- Harder to rotate without breaking pipelines
- More likely to leak (it exists for months)
- Often over-scoped “to avoid CI failures”
For many APIs you control, a better pattern is: the CI job authenticates, mints a short-lived access token, and uses it only inside the run.
You can implement that directly in YAML flows via request chaining: step 1 fetches a token, subsequent steps reference it.
Example: OAuth client credentials minted inside a YAML flow
This pattern keeps the access token out of Git, and makes the dependency explicit in the flow.
name: staging-regression
steps:
- name: oauth_token
request:
method: POST
url: "{{ env.AUTH_BASE_URL }}/oauth/token"
headers:
content-type: application/x-www-form-urlencoded
body: "grant_type=client_credentials&client_id={{ env.OAUTH_CLIENT_ID }}&client_secret={{ env.OAUTH_CLIENT_SECRET }}&scope={{ env.OAUTH_SCOPE }}"
assert:
- status: 200
extract:
access_token: "$.access_token"
token_type: "$.token_type"
- name: create_widget
request:
method: POST
url: "{{ env.API_BASE_URL }}/widgets"
headers:
authorization: "{{ steps.oauth_token.extract.token_type }} {{ steps.oauth_token.extract.access_token }}"
content-type: application/json
body:
name: "ci-{{ env.RUN_ID }}"
assert:
- status: 201
extract:
widget_id: "$.id"
- name: delete_widget
request:
method: DELETE
url: "{{ env.API_BASE_URL }}/widgets/{{ steps.create_widget.extract.widget_id }}"
headers:
authorization: "{{ steps.oauth_token.extract.token_type }} {{ steps.oauth_token.extract.access_token }}"
assert:
- status: 204
Notes that matter in CI:
- The token is minted at runtime, so rotation mostly moves to the client secret, not an access token copied into multiple places.
- The flow is deterministic: it creates a unique resource and cleans it up.
- The auth wiring is reviewable in Git because it is native YAML, not UI state.
If you are building flows from recorded browser traffic (HAR), you typically want to replace replayed session cookies or copied bearer tokens with this explicit “mint token then chain” step. (If you work with HAR, treat it as sensitive by default, see How to Redact HAR Files Safely.)
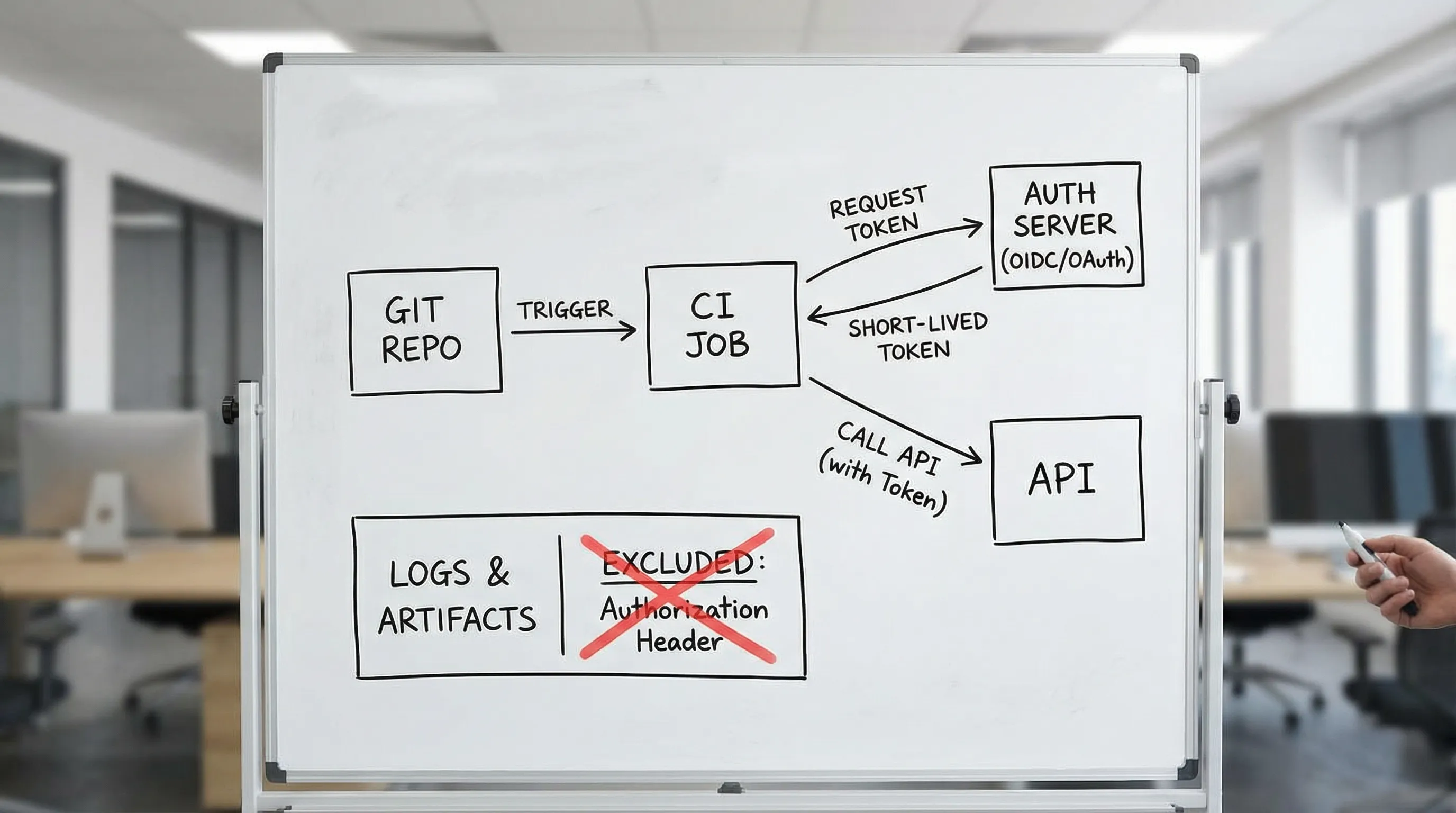
When you must use static API tokens, make them rotation-friendly
Sometimes you cannot mint a token per run:
- Third-party vendor APIs that only support API keys
- Legacy internal systems
- Rate-limited auth servers where minting per shard is expensive
If you must use static secrets, design for overlap rotation.
The “two-token overlap” pattern
Keep two secrets in your CI secret store:
API_TOKEN_ACTIVEAPI_TOKEN_NEXT
Your runner uses API_TOKEN_ACTIVE. During rotation, you:
- Create a new token, store it as
API_TOKEN_NEXT - Deploy token acceptance changes if needed (some APIs require allowlisting)
- Flip which one is active (rename, or change a pointer variable)
- Revoke the old token after a safe window
In YAML, you reference a single environment variable that CI maps to the active secret.
steps:
- name: list_widgets
request:
method: GET
url: "{{ env.API_BASE_URL }}/widgets"
headers:
authorization: "Bearer {{ env.API_TOKEN }}"
assert:
- status: 200
CI decides what API_TOKEN means today.
Rotation cadence (pragmatic defaults)
| Token type | Suggested rotation | Why |
|---|---|---|
| Short-lived access token (minted per run) | Every run | The “rotation” is the TTL. |
| OAuth client secret used by CI | 30 to 90 days | Enough time to coordinate, not so long that it becomes forgotten. |
| Static API key (vendor) | 30 to 60 days (if possible) | Reduce blast radius of leaks. |
| Personal access token (PAT) used in CI | Avoid, otherwise 14 to 30 days | PATs tend to be over-scoped and under-audited. |
The exact cadence depends on your incident response requirements, but the anti-pattern is “never rotate because it breaks CI sometimes”.
Secret hygiene: prevent leaks in Git, logs, and artifacts
Most token leaks in CI are self-inflicted. Common sources:
- Raw HAR files committed to the repo
- “Temporary debug” printing headers
- JUnit or JSON reports embedding request dumps
- CI artifacts containing full request/response logs
Git hygiene: commit contracts, not secrets
A good repo layout commits:
- Flows (YAML)
- Environment templates (non-secret)
- Fixtures (sanitized)
And ignores:
- Local override env files
- HAR captures
- Runner output
Example .gitignore snippet:
# HAR captures can contain cookies, bearer tokens, and PII
*.har
# Local env overrides should never be committed
.env
.env.*
**/*local*.yml
# Runner output
artifacts/
reports/
This is where YAML helps over Postman/Newman: with Postman, teams often export an “environment” JSON, then someone accidentally commits it with real token values. With YAML-first flows, the pattern is naturally “reference env var”, and the PR diff stays readable.
Bruno is closer to Git-first than Postman, but it is still a custom DSL (.bru) and teams often end up with separate environment files and runner conventions. Native YAML keeps the test definition in a broadly understood format and avoids tool-specific serialization noise.
Log hygiene: assume your CI output is public within your org
Practical rules:
- Never print tokens, even masked, unless you are in an incident.
- Avoid
set -xin shells that run API tests. - Do not dump full request headers on failure by default.
- Treat artifacts as sensitive, especially if they include HTTP traces.
If you need debuggability, aim for structured failure output (status code, endpoint, assertion mismatch, correlation ID) instead of raw headers.
For auditable, minimal artifacts, store what you need to reproduce without leaking secrets. A good reference is Auditable API Test Runs: What to Store.
HAR hygiene: redact before converting to tests
If you generate YAML flows from real browser traffic, redaction is not optional. HAR often includes:
Authorizationheaders- Cookies (session tokens)
- CSRF tokens
- PII in request bodies
The safe workflow is: capture narrowly, redact aggressively, then convert to YAML and replace replayed sessions with explicit auth steps. See How to Redact HAR Files Safely.
Token handling for chained workflows (request chaining without auth flake)
Multi-step flows magnify token mistakes because the same token must survive multiple calls, sometimes across shards.
Fail fast: add a “whoami” or “token introspection” preflight
A cheap preflight makes auth failures obvious and keeps your CI signal clean.
steps:
- name: whoami
request:
method: GET
url: "{{ env.API_BASE_URL }}/me"
headers:
authorization: "Bearer {{ env.API_TOKEN }}"
assert:
- status: 200
- jsonpath: "$.role"
equals: "ci-regression"
That last assertion is underrated: it catches “someone swapped secrets” problems early.
Avoid cross-step token mutation
In Postman/Newman setups, it is common to mutate environment variables from scripts, which is powerful but easy to get wrong when you run in parallel. In YAML-based flows, prefer a pattern where:
- Step A extracts
access_token - Steps B to N reference
steps.A.extract.access_token - You do not overwrite a global variable midway through the run
This is one of the simplest ways to keep chains deterministic under CI sharding and multithreading.
For more on chaining patterns (IDs, headers, cookies, cleanup), see API Chain Testing: How to Test Multi-Request Sequences Automatically.
CI integration: keep secrets in the CI system, keep wiring in Git
Your YAML should describe:
- Which env vars it expects (
API_BASE_URL,API_TOKENor OAuth credentials) - How token acquisition chains into subsequent requests
Your CI should provide:
- The actual secret values
- Environment scoping rules (staging vs prod)
- Access control (who can run which jobs)
GitHub Actions example: mapping a rotated secret into a stable env var
name: api-tests
on:
pull_request:
jobs:
smoke:
runs-on: ubuntu-24.04
permissions:
contents: read
env:
API_BASE_URL: ${{ vars.STAGING_API_BASE_URL }}
API_TOKEN: ${{ secrets.API_TOKEN_ACTIVE }}
RUN_ID: ${{ github.run_id }}
steps:
- uses: actions/checkout@v4
- name: Run smoke flows
run: |
# Replace with your DevTools CLI invocation
devtools run flows/smoke/*.yml
A few non-obvious points:
- Use GitHub Environments for staging/prod separation if you need approvals and scoped secrets.
- Consider that PRs from forks typically do not have access to secrets. For those, run a no-secret lint job (YAML validation, formatting, static checks) and keep secret-backed runs for trusted contexts.
If you are standardizing CI execution and reports, align with the CI-native patterns in API Testing in CI/CD: From Manual Clicks to Automated Pipelines.
The sharp edges (and how to avoid them)
“Admin token” is not a shortcut, it is technical debt
It makes tests pass today, and creates long-term failures:
- You stop catching missing-permission bugs.
- You cannot safely share artifacts.
- A leak becomes a security incident, not just a CI incident.
Use a separate privileged identity only for setup/teardown that cannot be done otherwise, and keep it out of the main regression runner.
Token reuse across parallel shards can trigger rate limits
If your auth server is rate-limited, minting a token per shard may overload it. In that case:
- Mint one token per job (not per step)
- Reuse it across the steps in that job
- Reduce shard concurrency if needed
This is a balancing act between least privilege, determinism, and infra limits. If rate limits are a recurring issue, treat them as part of the CI contract (inspect rate-limit headers, tune concurrency). See related patterns in API Testing in GitHub Actions: Secrets, Auth, Retries, Rate Limits.
Pin your runner and action versions so rotation is the only variable
Token issues are hard enough without “the runner updated and now logs headers differently”. Pin your CI dependencies and print versions. A good starting point is Pinning GitHub Actions + Tool Versions: Stop CI Breakage.
A minimal checklist you can enforce in PR review
Treat token handling like production code. Review it.
- YAML references env vars for secrets, never inline values.
- Auth is either minted per run (preferred) or uses an overlap-rotation scheme.
- Token scopes match suite intent (smoke vs regression vs negative auth).
- Preflight step fails fast for 401/403 with a clear assertion.
- Logs and artifacts do not include
Authorization, cookies, or raw HAR.
This is where Git-first, native YAML workflows tend to beat Postman/Newman setups: the exact auth wiring is visible, diffable, and enforceable as a merge gate.
If you are moving off Postman collections for CI, the migration mechanics are covered in Migrate from Postman to DevTools, but token hygiene should be part of the plan from day one.