 Star on GitHub
Star on GitHub
API Testing in 2026: YAML Definitions, GitOps Workflows, and the Death of Manual Testing
Manual API testing is not “dead” because developers stopped caring. It is dying because the delivery model changed.
In 2026, most teams ship through merge queues, feature flags, progressive delivery, and automated rollbacks. The bottleneck is no longer writing code, it is proving changes are safe, quickly, with artifacts you can audit later. GUI-driven API checks (clicking around in Postman workspaces, running collections locally, copy-pasting screenshots into tickets) simply do not compose with that reality.
What replaces it is not one tool, but a set of converging patterns:
- YAML as the test definition (human-readable, diffable, reviewable).
- Git-native workflows (PR review, CODEOWNERS, branch protection, merge queues).
- Traffic-based test generation (HAR, proxy captures, “record then stabilize”).
- AI-assisted authoring (not “AI tests,” but AI that helps you draft and normalize safely).
- Trace-based testing (asserting distributed behavior, not only HTTP responses).
This article is a trend analysis plus a practical guide for experienced developers building CI-native API regression suites. It leans into determinism, request chaining, and GitOps mechanics, and compares the new workflow against Postman, Newman, and Bruno. DevTools is used as the concrete reference point because it matches these patterns: native YAML flows, HAR to YAML conversion, and a local-first runner designed for CI.
The 2026 shift: API tests became merge artifacts, not “QA activities”
The biggest change is not syntax. It is where API tests live and how they are governed.
In 2026, effective API suites behave like code:
- Test definitions live in Git.
- Diffs are reviewed in PRs.
- Results are emitted as machine-readable artifacts (JUnit, JSON, logs).
- Failures are triaged with minimal, reproducible context.
- The suite is runnable locally with the same entrypoints as CI.
That has a few downstream consequences.
GUI-first tools hit three hard limits
1) Reviewability and diff noise
If the source of truth is a UI workspace, reviewers do not see what changed. Even when there is an “export” option, the artifact is often noisy, reordered, and hard to reason about.
2) Determinism under CI constraints
CI runners are ephemeral, parallel, and locked down. Anything that relies on sticky local state, implicit cookies, or manually curated environments tends to flake.
3) Governance and provenance
When a test fails in a merge queue, you need to answer:
- What exact test definition ran?
- With which tool version?
- Against which environment?
- What inputs were used?
If your test definition is a UI workspace plus personal environment variables, the audit trail is weak.
The new baseline: “tests are pull-request content”
The teams that scaled API testing did something simple: they made tests boring.
- Text files.
- Stable formatting.
- Small diffs.
- Pin versions.
- Structured output.
This is what people usually mean by “api testing best practices 2026.” It is less about adding more assertions, and more about making the suite operate like any other critical CI gate.
YAML-as-test-definition: why YAML won (and what “native YAML” actually means)
YAML is not magical. It just hits the right tradeoffs for API workflows:
- Readable enough to review.
- Writable enough to hand-edit.
- Composable with Git tooling.
- Strict enough to support stable conventions.
The important part is native YAML, not “YAML exported from a UI.” Native YAML means:
- The YAML file is the source of truth.
- The runner reads it directly.
- The tool does not roundtrip it through a proprietary internal model that reorders keys and causes diff churn.
That’s the practical difference between a Git-native YAML suite and “exported collections.”
YAML as an interface boundary
When YAML is the interface boundary, teams can build real workflows around it:
- Pre-commit hooks for linting and redaction
- CODEOWNERS for critical flows
- Review guidelines for assertions
- Test sharding by file path
- Deterministic formatting rules
DevTools leans into this model, and has published conventions specifically to keep diffs readable (see YAML API test file structure conventions and Git-friendly YAML formatting rules). Even if you do not use DevTools, the conventions are the point: YAML is only “Git-friendly” if you treat it like code.
A minimal YAML flow that actually survives CI
Below is a representative pattern: authenticate, create a resource, verify, then delete. The key is explicit capture and chaining, not “remembered state.”
name: user-crud-smoke
vars:
base_url: ${ENV.BASE_URL}
run_id: ${RANDOM.UUID}
steps:
- name: health
request:
method: GET
url: ${vars.base_url}/health
assert:
status: 200
- name: login
request:
method: POST
url: ${vars.base_url}/auth/login
headers:
content-type: application/json
body:
email: ${ENV.SMOKE_USER_EMAIL}
password: ${ENV.SMOKE_USER_PASSWORD}
capture:
token: $.json.token
assert:
status: 200
json:
- path: $.json.token
exists: true
- name: create_user
request:
method: POST
url: ${vars.base_url}/users
headers:
authorization: Bearer ${steps.login.capture.token}
content-type: application/json
body:
email: smoke+${vars.run_id}@example.com
displayName: Smoke ${vars.run_id}
capture:
user_id: $.json.id
assert:
status: 201
json:
- path: $.json.id
type: string
- name: get_user
request:
method: GET
url: ${vars.base_url}/users/${steps.create_user.capture.user_id}
headers:
authorization: Bearer ${steps.login.capture.token}
assert:
status: 200
json:
- path: $.json.email
equals: smoke+${vars.run_id}@example.com
- name: delete_user
request:
method: DELETE
url: ${vars.base_url}/users/${steps.create_user.capture.user_id}
headers:
authorization: Bearer ${steps.login.capture.token}
assert:
status:
anyOf: [200, 204]
What makes this “2026-ready” is boring discipline:
- No hard-coded secrets, only environment variables.
- Unique run IDs to avoid collision in parallel CI.
- Assertions focused on invariants, not volatile fields.
- Captures instead of implicit state.
If your YAML runner cannot do this cleanly, your suite will eventually drift back into manual rituals.
GitOps workflows for API tests: the mechanics that replaced “run it locally”
Calling it “GitOps” can sound grand, but the mechanics are simple: treat API tests like any other production-impacting code.
PR review is where test quality is enforced
Two 2026 patterns are now common in mature teams:
1) PRs must update tests when behavior changes
If an endpoint changes but flows are not updated, the PR is incomplete. This is easiest to enforce when the tests are text files that live in the same repo and get reviewed in the same PR.
2) API test ownership is explicit
- CODEOWNERS on sensitive flows (auth, payments, entitlements).
- Required reviewers for changes to core workflows.
- Review checklists tailored to flake prevention.
A practical guide to this style of workflow is Git workflow for YAML API tests.
CI gating evolved into two tiers
Most teams converge on a two-tier structure:
- PR gate (fast): smoke flows, contract checks, quick invariants.
- Post-merge (deep): heavier regression suites, eventual-consistency checks, load-adjacent validations.
This matches how merge queues behave. A merge queue wants fast, deterministic answers for “is this safe to merge?” and deeper answers after merge for “did we regress something subtle?”
DevTools’ guides cover this split explicitly for CI-native suites (for example, API testing in CI/CD and API regression testing in GitHub Actions). If you already have a CI runner, the important part is the organization and artifact model.
Auditable artifacts became non-negotiable
When tests are gates, results must be auditable. The “store everything” instinct is dangerous because responses often contain secrets or PII.
A pragmatic model that is increasingly standard:
- Store test definitions (YAML) in Git.
- Store run artifacts (JUnit XML, logs, a run manifest) as CI artifacts.
- Avoid storing raw traffic captures (HAR) unless redacted.
This matches the guidance in Auditable API test runs.
Request chaining in 2026: correlation is the test
The most common “mature suite” failure is not a missing assertion. It is a missing correlation.
A large share of production bugs are workflow bugs:
- A token is minted but not accepted by a downstream service.
- Create succeeds but read returns stale data.
- Side-effect delivery fails (webhook, message, email).
- Permissions are inconsistent across endpoints.
This is why multi-step API workflows have become core, not optional. DevTools has written about this in depth (see why single-request API tests miss real bugs and API chain testing). The broader industry trend is the same: endpoint checks are necessary, but insufficient.
Determinism techniques that matter more than “more tests”
If you are building workflows, your main enemy is flake. The most effective 2026 techniques are:
- Idempotency keys for POST-like operations.
- Unique correlation IDs per run.
- Explicit teardown or “garbage collectible” resources.
- Polling with bounded timeouts for eventual consistency.
- Assertions on invariants, not full snapshots, unless you canonicalize.
Here is a polling pattern that is explicit and bounded. (Exact syntax varies by runner, but the idea is consistent.)
name: wait-for-indexing
vars:
base_url: ${ENV.BASE_URL}
steps:
- name: create
request:
method: POST
url: ${vars.base_url}/documents
headers:
authorization: Bearer ${ENV.TOKEN}
content-type: application/json
body:
title: "Index me"
capture:
doc_id: $.json.id
assert:
status: 201
- name: poll_until_searchable
loop:
max_attempts: 20
sleep_ms: 500
until:
json:
- path: $.json.total
gte: 1
request:
method: GET
url: ${vars.base_url}/search?q=Index%20me
headers:
authorization: Bearer ${ENV.TOKEN}
assert:
status: 200
The important part is not “loop support.” It is boundedness: max attempts, sleep, and a predicate that expresses what “ready” means.
Assertions moved from “exact match” to “contracted invariants”
Snapshot testing is still useful, but most teams became more selective because unstable fields (timestamps, IDs, sorting) make snapshots expensive.
The stable approach is:
- Assert schema or types broadly.
- Assert a few critical invariants (ids, totals, specific flags).
- Canonicalize only where snapshots are truly valuable.
If you want practical patterns, DevTools’ deterministic API assertions is aligned with how most CI suites look in 2026.
Traffic-based test generation: HAR became the new “record” button
The trend that quietly changed suites is this: tests are increasingly derived from real traffic.
Not because “recording is easier,” but because traffic provides:
- The real request shape (headers, cookies, CSRF patterns).
- The real sequence (auth, redirects, follow-ups).
- The real edge cases (feature flags, version headers).
Why HAR specifically won mindshare
HAR (HTTP Archive) is a well-supported export format from browsers and proxies, which makes it a convenient interchange for “what actually happened.”
- It is easy to capture.
- It is concrete.
- It includes enough detail to reconstruct calls.
The catch is that raw HAR is not a good test artifact:
- It contains secrets.
- It contains noise.
- It contains one-off values that make replay flaky.
So the emerging pipeline is:
- Capture a minimal HAR for a bounded workflow.
- Sanitize and redact it.
- Convert it into a workflow definition.
- Normalize the workflow for determinism.
- Commit the resulting YAML, not the HAR.
DevTools is built around this pipeline (see Chrome DevTools Network to YAML flow and how to redact HAR files safely).
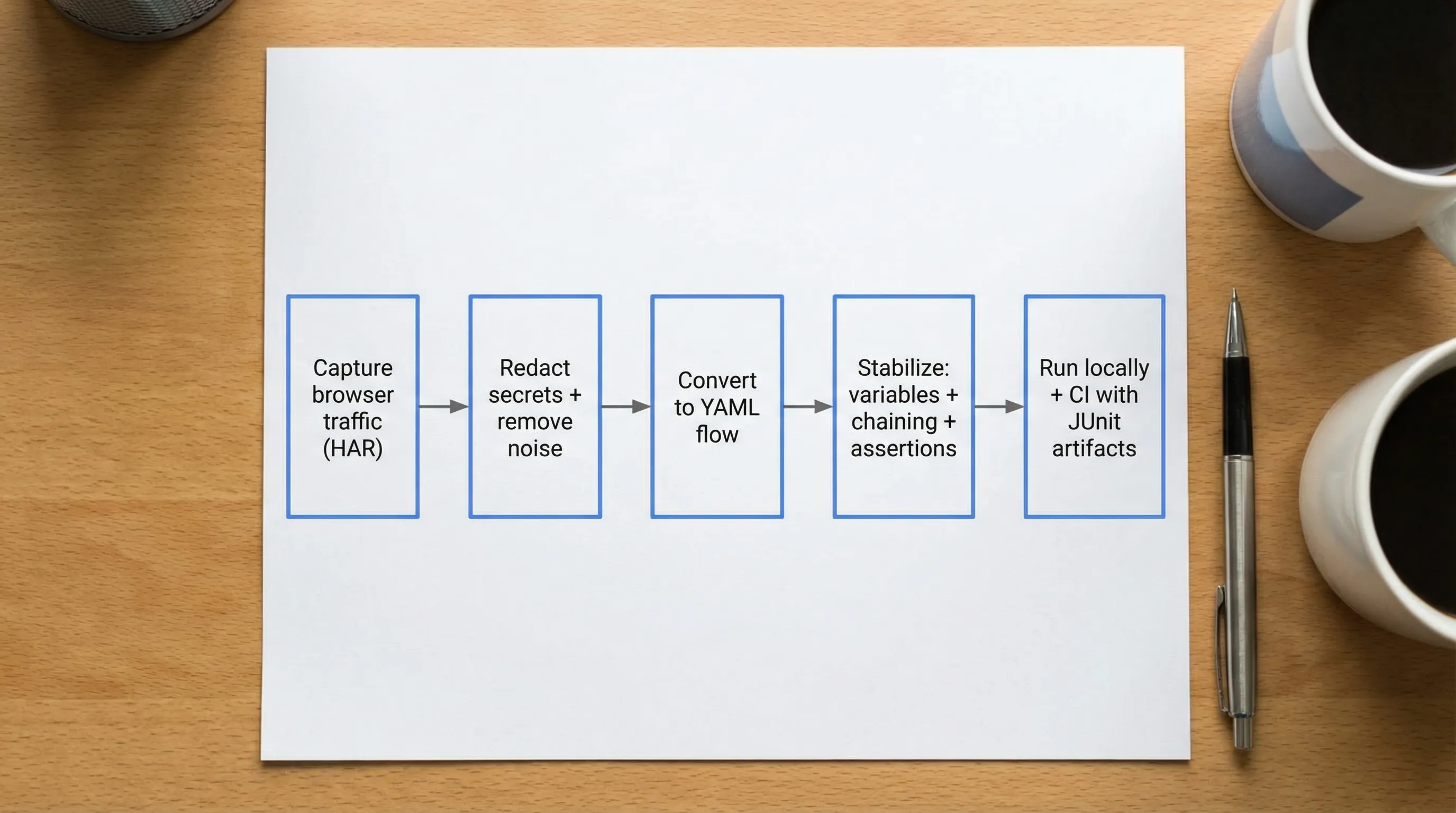
What “stabilizing recorded traffic” actually means
Recorded traffic is inherently environment-specific. Stabilization usually requires the same set of edits:
- Replace auth cookies and tokens with explicit login steps.
- Remove browser-only headers (sec-fetch-*, accept-language churn, etc.).
- Parameterize secrets as environment variables.
- Convert one-off IDs into captured variables.
- Add deterministic assertions.
A recorded call often looks like “POST /checkout” with a body containing transient ids. A stabilized call becomes:
- Create a cart.
- Capture cart_id.
- Add items.
- Capture checkout_id.
- Confirm.
This is why traffic-based generation is not “push button test creation.” It is a fast way to get the correct skeleton.
Why traffic-based generation beats “write from scratch” in one critical category
In modern web stacks, request correctness frequently depends on invisible coupling:
- CSRF tokens.
- SameSite cookie behavior.
- Anti-bot headers.
- Versioned headers.
- Correlation headers.
When you write tests from scratch, you often rediscover these constraints by failing in CI. When you start from captured traffic, the coupling is visible immediately, then you can decide what to keep versus what to eliminate for testability.
AI-assisted test creation: useful, but only with hard constraints
AI did not replace API tests in 2026. It replaced some of the typing.
Where it helps most:
- Drafting assertions from example responses.
- Suggesting which fields are stable versus volatile.
- Proposing normalization rules (drop timestamps, sort arrays).
- Generating negative cases (missing auth, invalid enum, boundary values).
Where it hurts:
- Inventing fields that do not exist.
- Overfitting to one captured response.
- Generating brittle “assert everything” snapshots.
A workable 2026 pattern: “AI drafts, humans pin invariants”
If you want AI in this workflow without destroying determinism, constrain it:
- Feed it one sanitized example response and a list of known invariants.
- Ask it to propose assertions grouped by stability.
- Require reviewers to approve each invariant.
- Encode the invariants in YAML, not in a tool-specific prompt history.
Example prompt outcome you actually want (expressed as YAML):
- name: get_account
request:
method: GET
url: ${vars.base_url}/account
headers:
authorization: Bearer ${steps.login.capture.token}
assert:
status: 200
json:
- path: $.json.id
type: string
- path: $.json.email
matches: "^[^@]+@[^@]+$"
- path: $.json.plan
anyOf: [free, pro, enterprise]
- path: $.json.createdAt
matches: "^\\d{4}-\\d{2}-\\d{2}T"
That last line is subtle: you are not asserting the exact timestamp, you are asserting it is shaped like a timestamp.
Treat AI output like untrusted input
In practice, teams that adopted AI-assisted authoring successfully put it behind the same gates as any other contribution:
- YAML linting and formatting.
- Secret scanning.
- CI run on PR.
- Human review.
AI is helpful when it accelerates conversion of known intent into test code. It is harmful when it becomes a second, unreviewed source of truth.
Trace-based testing: from “did the endpoint respond” to “did the system behave”
In 2026, most production systems are not a single service. They are a graph.
HTTP-level tests tell you “this endpoint returned 200.” Trace-level tests can tell you:
- Did the request touch the expected downstream services?
- Were retries triggered?
- Did we hit the fallback path?
- Did we stay within latency budgets?
This is why trace-based testing is emerging as a complement to workflow tests.
The key idea: propagate trace context, then assert on spans
You can make workflow tests trace-aware without special runner features:
- Generate a unique trace identifier per test run.
- Send it via standard trace headers.
- Query your tracing backend via its API.
For trace context propagation, the relevant standard is W3C Trace Context (many OpenTelemetry setups support it).
Below is a conceptual YAML flow:
name: checkout-trace-aware
vars:
base_url: ${ENV.BASE_URL}
trace_id: ${RANDOM.HEX_32}
traceparent: "00-${vars.trace_id}-0000000000000001-01"
steps:
- name: checkout
request:
method: POST
url: ${vars.base_url}/checkout
headers:
authorization: Bearer ${ENV.TOKEN}
content-type: application/json
traceparent: ${vars.traceparent}
body:
cartId: ${ENV.CART_ID}
assert:
status: 200
- name: query_traces
request:
method: GET
url: ${ENV.TRACING_QUERY_URL}?trace_id=${vars.trace_id}
headers:
authorization: Bearer ${ENV.TRACING_QUERY_TOKEN}
assert:
status: 200
json:
- path: $.json.spans
exists: true
- path: $.json.spans[*].service
containsAll: [api, payments, inventory]
Two notes:
- The exact query URL depends on your tracing backend (Jaeger, Tempo, Honeycomb, etc.). The pattern is what matters.
- Do not assert too much. Trace data can be noisy. Focus on invariants such as “payments service was invoked” or “no error spans.”
Trace-based assertions that tend to stay stable
The trace checks that survive long-term are typically:
- Presence or absence of an error span.
- Service boundary expectations for critical workflows.
- Upper bounds on end-to-end latency (with slack).
- Counts within a range (not exact).
This complements YAML workflow testing: YAML validates request and response semantics, traces validate distributed execution.
Git-native testing tools: what teams are replacing Postman, Newman, and Bruno with
Postman and Newman are still everywhere in 2026, but their role is shifting.
Postman: still great for exploration, weaker as CI source of truth
Postman’s strengths remain:
- Great interactive client.
- Good collaboration UX.
- Easy onboarding.
But the friction points for CI-centric teams are consistent:
- Test definitions often live in the Postman ecosystem first, Git second.
- PR review of changes is awkward.
- Script-heavy collections become hard to govern.
- CI pipelines end up depending on exported artifacts.
Newman improves the “run in CI” story, but not the “definition is Git-first” story, because you still run Postman collection JSON plus environment files.
DevTools’ migration content exists because this pattern repeats in many teams (see Migrate from Postman and Newman alternative for CI).
Bruno: Git-friendly, but still a custom format
Bruno deserves credit for pushing local files and Git workflows. The tradeoff is that it introduces another DSL (its own file format) and an ecosystem around it.
In practice, some teams are fine with a custom DSL. Others prefer YAML because:
- It is a broadly understood data format.
- It has existing tooling (linters, formatters, schema validators).
- It is easier to treat as a shared “interface” across systems.
The industry trend is toward standard-ish text artifacts (YAML, JSON, HCL) that slot into Git workflows cleanly.
What DevTools aligns with in this trend
Based on the public description and guides, DevTools aligns with three 2026 directions:
- Native YAML workflows (not exported snapshots of a UI state).
- Traffic-based generation from browser HAR captures.
- Local-first execution and CI execution with structured reports.
Crucially, the artifact is plain YAML that you can review in a PR. That is the core shift.
A practical 2026 reference workflow: from capture to PR gate
If you want to implement these trends without boiling the ocean, this is a realistic adoption path.
Step 1: pick the workflows that actually cause incidents
Start from production reality, not endpoint coverage:
- Auth and session refresh.
- Checkout and payment authorization.
- Provisioning and entitlements.
- Webhook delivery.
- “Create then read” flows that power user-facing UIs.
Step 2: generate the skeleton from traffic
Capture a bounded HAR and convert it.
If you are using DevTools, the specific pipeline is documented in HAR to YAML and related posts.
Even if you are not, the principle holds: record real traffic, then stabilize it.
Step 3: stabilize for determinism
The stabilization phase is where suites are made or broken. Your checklist should include:
- Replace secrets with environment variables.
- Remove volatile headers.
- Replace hard-coded IDs with captures.
- Add explicit teardown.
- Add bounded polling.
- Assert invariants.
Step 4: commit YAML flows and enforce review
Set up:
- A stable YAML style.
- CODEOWNERS for core flows.
- A PR checklist for flake prevention.
Step 5: run a fast shard on every PR
Your PR gate should:
- Install a pinned runner version.
- Run smoke workflows.
- Emit JUnit artifacts.
- Fail fast with actionable output.
If you want a concrete CI example for DevTools YAML flows, use the existing guide instead of reinventing it: API regression testing in GitHub Actions.
Step 6: run deep suites post-merge
After merge:
- Run bigger suites.
- Increase timeouts for eventual consistency.
- Run against staging and optionally canary.
- Store artifacts with a retention policy.
How YAML changes the day-to-day engineering loop
Once tests are YAML in Git, a few things become easier in ways that are hard to appreciate until you live with them.
Code review becomes meaningful
Instead of reviewing “Postman collection updated,” you review a diff like:
- Header removed.
- Assertion tightened.
- Capture added.
- Polling bound increased.
That is a concrete engineering conversation.
Merge conflicts become solvable
UI-locked formats tend to cause broad, noisy diffs where unrelated edits conflict. YAML can still conflict, but stable conventions dramatically reduce it.
You can build tooling around tests
When tests are plain text, you can:
- Enforce patterns (no hard-coded base URLs).
- Autogenerate docs.
- Map ownership.
- Shard by file path.
This is where “death of manual testing” actually lands. It is not that humans never run a test manually. It is that the system no longer depends on humans to create confidence.
A 2026 checklist: what “good” looks like
Use this as a calibration list for a CI-first, Git-native suite.
| Category | 2026 expectation | Practical signal |
|---|---|---|
| Definition | Tests are text files in Git | PR diffs show real changes |
| Execution | Same entrypoint locally and in CI | make test-api works everywhere |
| Determinism | No implicit state, bounded retries | Few flakes, reproducible failures |
| Chaining | Captures and correlation IDs | No hard-coded resource IDs |
| Secrets | Zero secrets committed | CI uses secret store or OIDC |
| Reporting | JUnit + logs as artifacts | Failures show up in PR UI |
| Governance | Ownership and required checks | CODEOWNERS, branch protection |
| Generation | Traffic-derived skeletons | HAR capture pipeline exists |
| Observability | Trace-aware for critical flows | Trace id propagated and queried |
If you are missing one, that is usually where the next year of pain comes from.
FAQ
Is YAML really better than Postman collections for CI? YAML is not inherently better, but native YAML definitions are easier to review, diff, shard, and govern in Git. Postman collections can run in CI (often via Newman), but many teams struggle with reviewability and determinism when the UI workspace is the primary source of truth.
How do I avoid flaky multi-step workflow tests? Make dependencies explicit (captures and chaining), use unique run IDs, avoid asserting volatile fields, bound retries and polling, and add teardown or idempotency keys so parallel CI runs do not collide.
Should we commit HAR files to Git? Usually no. HAR files often contain secrets, cookies, and PII, and they include noisy browser traffic. Prefer committing sanitized, deterministic YAML flows and treating raw HAR captures as transient inputs.
Where does AI fit without making tests unreliable? Use AI to draft assertions and identify volatile fields, but keep the final test definition in Git, enforce linting and secret scanning, and require human review. Treat AI output like untrusted input.
What is trace-based testing, and is it worth it? Trace-based testing validates distributed behavior (service boundaries, error spans, latency budgets) by propagating trace context and querying your tracing backend. It is most valuable for critical workflows where regressions happen across services, not within a single endpoint.
If you want to adopt this workflow without inventing your own toolchain
If your direction is YAML-first definitions, Git-native review, and traffic-derived workflows, DevTools is explicitly designed around that shape.
- It converts browser traffic (HAR) into human-readable YAML flows with auto-mapped variables.
- The YAML flows are meant to be committed, reviewed, and run locally or in CI.
- It is free and open-source, which matters when you want the artifact to outlive a vendor’s UI decisions.
Start with the most implementation-oriented entry points:
- Chrome DevTools Network to YAML flow: a repeatable pipeline
- API regression testing in GitHub Actions
- Migrate from Postman to DevTools
If you already have flows in Git and want a local-first runner, you can begin at the homepage: dev.tools.