 Star on GitHub
Star on GitHub
API Testing from Real Traffic: From HAR Capture to CI Gate
If your API tests don’t come from real traffic, you’re always guessing. You guess which headers matter, which IDs correlate across calls, which auth path the frontend actually uses, and which “optional” endpoints turn out to be required. That guesswork is why teams end up with brittle Postman collections, a pile of Newman scripts, and CI that’s either flaky or ignored.
A more deterministic approach is to start with a bounded HAR capture of a real user flow, convert it to native YAML, make dependencies explicit with request chaining, and then wire it into a CI gate that blocks merges when the workflow regresses.
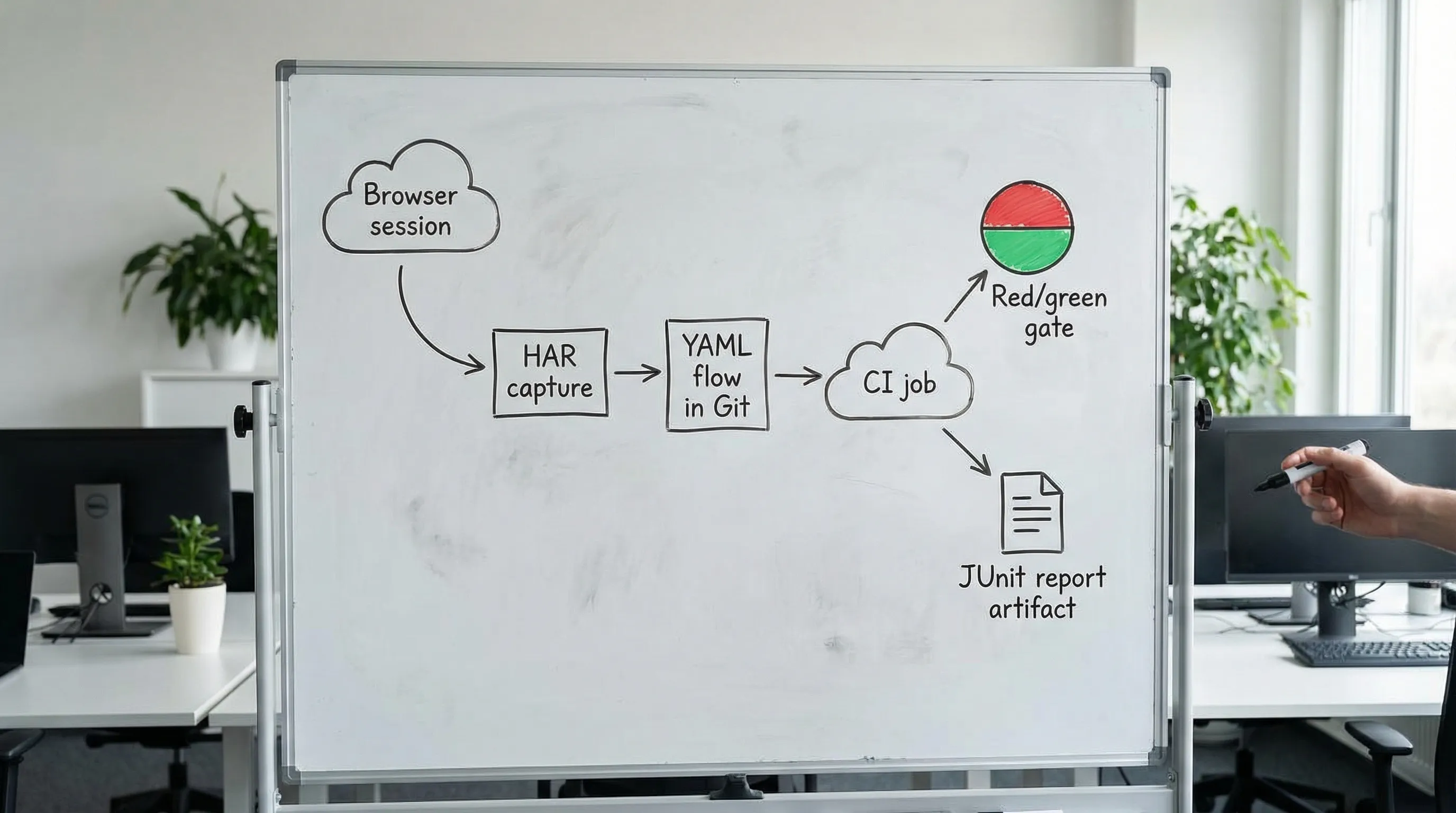
Why HAR-derived API tests catch regressions your hand-written tests miss
HAR-derived flows are not “UI tests”. They are API-level workflows sourced from what the browser actually did.
That matters for experienced teams because the bugs you care about are usually in the seams:
- The auth token you thought was a bearer token is actually minted via an exchange and cached with a cookie.
- A “create” request works, but the follow-up “read” depends on a header, query param, or eventual consistency window.
- A workflow silently relies on an idempotency key, CSRF token, or a correlation ID propagated across calls.
Recording traffic turns these from tribal knowledge into executable artifacts.
Capture a HAR that can survive CI
A HAR is only useful for API testing if it’s small, scoped, and reproducible.
Scope the capture to one business workflow
Don’t record “open the app and click around”. Record one bounded flow end to end:
- Login (or token refresh)
- The workflow action (create order, update profile, submit application)
- Any follow-up reads
- Cleanup (delete, cancel, revoke) if possible
If you are testing an integration workflow, this approach works well for third-party APIs too. For example, if your product calls a travel/visa provider, capture the exact sequence your app executes against a partner like SimpleVisa and replay that workflow in CI to detect breaking changes before release.
Export only what you need
Browser sessions include noise that makes replay flaky. Treat the HAR as raw material, not as the test.
| Category | Keep? | Why it matters for replay |
|---|---|---|
| API calls to your domain | Yes | This is the workflow surface you want to validate |
| Auth endpoints (token, refresh, CSRF) | Usually yes | Often required to make subsequent calls valid |
| Third-party analytics, ads, pixels | No | Pure noise, adds nondeterminism |
| Static assets (images, fonts) | No | Not part of API correctness |
| Browser-only headers (client hints, sec-*) | No | Not required by servers, changes frequently |
| Volatile headers (Date, If-None-Match) | Usually no | Makes diffs noisy and replays brittle |
Practical capture hygiene:
- Disable cache in the Network panel to avoid conditional requests.
- Filter to your API domain(s) while capturing.
- Export with content only when you need bodies for correlation or assertions.
If you want a repeatable checklist for clean exports, see the DevTools guide on exporting a clean HAR.
Convert HAR to YAML, then make the YAML the source of truth
The main mistake teams make is committing the HAR, or treating it as a long-term artifact. HARs are great for generation and debugging, but they are not great for code review.
The goal is:
- Commit YAML flows to Git (human-readable, diffable)
- Treat the HAR as temporary input or a short-lived artifact
This is where DevTools’ model differs from Postman/Newman and Bruno:
- Postman collections are JSON, and the “real logic” often lives in UI configuration plus scripts. Diffs are noisy, reviews are painful.
- Newman executes Postman collections, so you inherit those format constraints in CI.
- Bruno is file-based, but it still uses a tool-specific format/DSL and conventions.
- DevTools focuses on native YAML workflows that are meant to be reviewed like code.
When your tests are plain YAML, you can:
- Code review changes in PRs without opening a UI
- Keep stable diffs (one logical change per line)
- Apply standard Git workflows (CODEOWNERS, branch protection, required checks)
If you care about keeping diffs readable, adopt consistent conventions (stable key ordering, sorted headers, no re-serialization churn). DevTools has a solid set of rules in YAML API test file structure conventions.
Turn “recorded” requests into deterministic chained steps
A recorded HAR gives you a chronological list of requests. A CI-worthy test needs explicit dependencies, variable extraction, and assertions that target invariants.
A practical chaining pattern (token -> create -> read -> delete)
Below is an example of what a replayable YAML workflow typically looks like after you trim noise and make correlations explicit.
Key ideas:
- Extract a token once and reuse it.
- Generate a unique run ID so parallel CI runs do not collide.
- Capture created IDs from responses and feed them into later requests.
- Include cleanup so retries do not compound state.
name: orders_smoke
vars:
base_url: ${BASE_URL}
run_id: ${RUN_ID}
steps:
- name: auth_login
request:
method: POST
url: ${base_url}/oauth/token
headers:
content-type: application/json
body:
client_id: ${CLIENT_ID}
client_secret: ${CLIENT_SECRET}
grant_type: client_credentials
extract:
access_token:
jsonpath: $.access_token
assert:
- status: 200
- jsonpath:
path: $.token_type
equals: Bearer
- name: create_order
depends_on: [auth_login]
request:
method: POST
url: ${base_url}/v1/orders
headers:
authorization: Bearer ${steps.auth_login.access_token}
content-type: application/json
idempotency-key: ${run_id}
body:
externalRef: ${run_id}
currency: USD
items:
- sku: test-sku
qty: 1
extract:
order_id:
jsonpath: $.id
assert:
- status: 201
- jsonpath:
path: $.externalRef
equals: ${run_id}
- name: read_order
depends_on: [create_order]
request:
method: GET
url: ${base_url}/v1/orders/${steps.create_order.order_id}
headers:
authorization: Bearer ${steps.auth_login.access_token}
assert:
- status: 200
- jsonpath:
path: $.id
equals: ${steps.create_order.order_id}
- name: delete_order
depends_on: [read_order]
request:
method: DELETE
url: ${base_url}/v1/orders/${steps.create_order.order_id}
headers:
authorization: Bearer ${steps.auth_login.access_token}
assert:
- status: 204
Notes for reviewers (the things that keep this CI-stable):
- Headers are minimal and sorted.
- IDs come from extraction, not hardcoding.
- Assertions avoid snapshotting entire payloads.
- State is isolated by
run_id.
Assertion strategy: validate invariants, not representations
HAR-derived traffic tempts you to assert everything. Don’t.
In CI, robust assertions are:
- Status codes
- Presence/type checks
- Subset matches for critical fields
- Explicit tolerances for floats/timestamps
If you need deeper patterns (array membership, timestamp normalization, tolerant numeric comparisons), use a consistent taxonomy and keep it in YAML so it stays reviewable. DevTools covers this well in JSON assertion patterns for API tests.
Designing the CI gate (what blocks merges, what runs later)
A “CI gate” is not synonymous with “run everything”. It’s a small, deterministic suite that protects main.
A practical split:
| Suite | Runs when | Purpose | Typical characteristics |
|---|---|---|---|
| PR gate (smoke) | On pull request | Block obvious workflow regressions | Fast, isolated, minimal external dependencies |
| Post-merge regression | On main push | Catch broader compatibility issues | Larger surface, more endpoints and edge cases |
| Nightly/weekly | Scheduled | Deep checks and drift detection | Heavier, can include load-ish parallelism |
Your HAR-derived flows are great candidates for the PR gate if you keep them bounded.
Minimal GitHub Actions gate (YAML flows + reports)
The implementation details vary by runner, but the shape should be consistent:
- Pull flows from the repo
- Provide secrets via CI secret store
- Run the YAML flow runner
- Emit JUnit so the CI UI can annotate failures
- Fail the job on non-zero exit codes
name: api-gate
on:
pull_request:
jobs:
smoke:
runs-on: ubuntu-24.04
timeout-minutes: 10
env:
BASE_URL: ${{ vars.BASE_URL }}
CLIENT_ID: ${{ secrets.CLIENT_ID }}
CLIENT_SECRET: ${{ secrets.CLIENT_SECRET }}
RUN_ID: ${{ github.run_id }}-${{ github.run_attempt }}
steps:
- uses: actions/checkout@v4
- name: Run YAML API flows
run: |
devtools run flows/smoke/*.yaml \
--report-junit artifacts/junit.xml \
--report-json artifacts/report.json
- name: Upload reports
if: always()
uses: actions/upload-artifact@v4
with:
name: api-test-artifacts
path: artifacts/
The important part is determinism, not the specific flags.
If you want more nuance on CI mechanics (parallel sharding, caching, retries, reporting), the DevTools guide API testing in CI/CD goes deep.
The hard parts (and how to keep the gate trustworthy)
A CI gate only works if failures are actionable. HAR-derived tests fail in predictable ways, and you can design around them.
Auth: eliminate reliance on captured sessions
Never replay a captured session cookie or token from the HAR.
Instead:
- Chain an explicit login/token exchange step.
- Put secrets in CI secret storage.
- Extract tokens at runtime and pass them forward.
This is one of the biggest advantages over UI-locked tools, where “it works on my machine” often means “my Postman environment has a token cached”.
Volatile values: treat them as variables, not literals
Common volatility sources:
- UUIDs and run-specific IDs
- Timestamps
- Pagination cursors
- Anti-CSRF tokens
If it changes per run, extract it and reference it.
Eventual consistency: bounded polling, not sleeps
If a workflow includes async propagation (create then immediately read), avoid sleep(5) logic hidden in scripts.
Prefer:
- Poll until a predicate is true
- Use a max attempt count
- Fail with a useful message when the condition never becomes true
This makes failures debuggable (you know what predicate never held), and keeps runtimes bounded.
Parallelism: isolate state or don’t parallelize
Running flows concurrently is great (especially with a fast local runner), but only if tests don’t fight over shared state.
Rules that scale:
- Generate unique resource names per run (
run_id). - Avoid global fixtures that are mutated.
- Make cleanup idempotent (delete should succeed even if the resource is already gone).
Reporting: store enough to debug, not enough to leak
CI failures need artifacts (logs and JUnit). Raw HAR files often contain secrets and PII.
A safe compromise:
- Commit YAML flows.
- Upload minimal logs and reports.
- Treat HAR files as local inputs or short-lived debug artifacts.
If you must share HAR data, redact it aggressively first. DevTools has a pragmatic guide on how to redact HAR files safely.
When HAR-derived API testing is not the right tool
This workflow is not universal. Avoid HAR-to-YAML as your primary strategy when:
- The “API” is mostly WebSockets or streaming where replay semantics differ.
- The workflow depends on external side effects you cannot control in CI (emails, SMS, human approvals) and you have no test doubles.
- You’re trying to validate broad contracts for many endpoints (contract/schema tests are often cheaper).
In practice, teams do best with a portfolio: contract checks for breadth, a small set of HAR-derived workflows for depth, and targeted edge-case tests for known failure modes.
A repeatable path from traffic to a merge-blocking gate
The stable loop looks like this:
- Capture one bounded workflow as a HAR.
- Convert to YAML.
- Trim noise, parameterize secrets, extract volatile values.
- Add request chaining and cleanup.
- Add invariant assertions.
- Commit the YAML to Git and enforce it as a PR check.
That loop is what makes “API testing from real traffic” worth doing. You end up with artifacts that are reviewable, deterministic, and CI-native, instead of a pile of UI state and opaque collection formats.