 Star on GitHub
Star on GitHub
API Chain Testing: How to Test Multi-Request Sequences Automatically
API chain testing is what breaks most “green” API suites the moment you try to run them like production: authenticate, create state, read it back, assert invariants, then clean up. The failures are rarely about a single endpoint returning the wrong status code. They are about state and dependencies: tokens, IDs, CSRF headers, optimistic locking, eventual consistency, and teardown that does not run when the test fails.
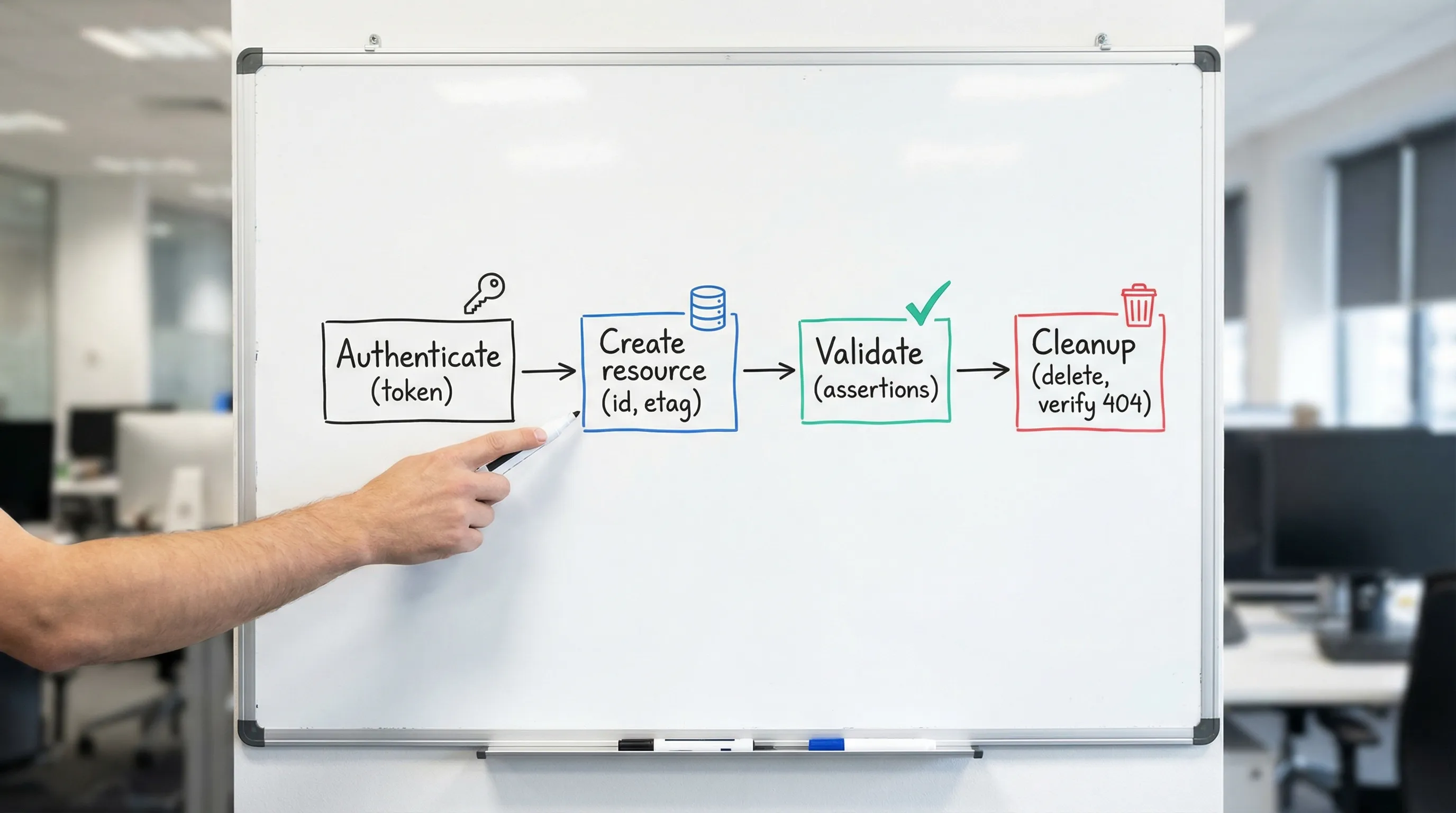
This tutorial shows a practical, Git-friendly way to test multi-request sequences automatically using YAML flows (DevTools style). We will build a deterministic chain:
- Authenticate (capture token)
- Create a resource (capture ID and ETag)
- Validate (assert schema-like invariants and business rules)
- Cleanup (delete resource, verify deletion)
Along the way, you will see patterns for:
- Variable extraction from JSON bodies and headers
- Chaining requests via explicit dependencies
- Assertions after every step (not just at the end)
- Error handling and teardown strategies that keep CI clean
If you want broader context on why single-request tests miss real bugs, see Why Single-Request API Tests Miss Real Bugs. If you need a bigger end-to-end structure, also review End-to-End API Testing: The Complete Guide. This post stays narrowly focused on chaining and the mechanics that make it deterministic.
What “API chain testing” actually means (for people who already test APIs)
In practice, “multi-request sequences” fall into a few dependency categories. Treating them explicitly is the difference between a stable CI suite and a pile of flaky runs.
| Dependency type | What you chain | Common source | Why it fails in CI if you ignore it |
|---|---|---|---|
| Auth | Access token, session cookie, CSRF token | Login/OIDC exchange, cookie jar, response headers | Token expiry, wrong audience/scope, CSRF mismatch, hidden cookie state |
| Resource identity | IDs, URLs, Location header | Create responses, Location header | Hardcoded IDs collide across runs, parallel jobs race |
| Concurrency control | ETag, version number, If-Match token | Response headers, body fields | Update tests pass locally, fail under concurrent writes |
| Pagination | cursor, next page token | Response body/Link header | Tests only validate page 1, miss ordering bugs |
| Side-effect completion | webhook delivery ID, job status | Async endpoints, queues | Eventual consistency makes “read after write” flaky |
Chain tests succeed when you:
- Extract only the values you need.
- Assert after each step so failures are localized.
- Make state unique per run so tests do not fight.
- Always clean up, even on failure, or make cleanup idempotent.
DevTools is designed for this style because flows are native YAML that you can commit, diff, and review in pull requests (instead of UI-locked collections or tool-specific DSLs). If your team is migrating, the mechanics here map directly to Migrate from Postman to DevTools.
Why YAML (and Git) is the right place for chaining
Chaining forces you to encode dependencies and state transitions. In a UI-first tool, that tends to become:
- hidden state in a “current environment”
- scripting glued across requests
- non-diffable changes because the artifact is an export format (often JSON with unstable ordering)
With YAML-first flows, the default workflow is:
- a stable file format
- reviewable diffs (including request bodies)
- predictable merges
- CI-native execution
If you care about keeping diffs clean over time, read YAML API Test File Structure: Conventions for Readable Git Diffs. It is the unglamorous part that prevents “tests as code” from turning into “tests as merge conflict”.
The example API we will test (replace with your real endpoints)
To keep the flow concrete, this tutorial assumes an API with these endpoints:
POST /auth/loginreturns{ "accessToken": "..." }POST /v1/projectscreates a project and returns{ "id": "...", "name": "..." }and anETagheaderGET /v1/projects/{id}returns the projectDELETE /v1/projects/{id}deletes it
Your API will differ. The patterns do not.
The determinism rules for the example
We will follow a few rules that make chain tests survive parallel CI runs:
- Every run uses a unique
run_idthat is included in created resource names. - We assert invariants, not incidental details (no brittle timestamp equality).
- Cleanup is idempotent (a second delete is not “failure”).
Repo layout and environment inputs
A minimal layout that scales:
flows/contains YAML flowsenv/contains non-secret environment templates- secrets come from CI secret stores (GitHub Actions secrets, Vault, etc)
Example:
.
├─ flows/
│ └─ project_chain_test.yaml
├─ env/
│ ├─ local.env.example
│ └─ ci.env.example
└─ README.md
Environment variables (example)
Put the shape in env/local.env.example and keep secrets out of Git:
BASE_URL=https://api.example.test
USERNAME=devtools-ci
PASSWORD=replace-me
RUN_ID=local-123
In CI, you typically set RUN_ID to something already unique (workflow run ID, job ID, commit SHA). The point is: make created resources traceable and non-colliding.
The full YAML flow (auth -> create -> validate -> cleanup)
Below is a complete flow file you can adapt. It is intentionally explicit. The YAML shows:
- extraction of
accessToken - chaining with
Authorization: Bearer ... - capture of
projectIdandprojectEtag - assertions between steps
- cleanup + deletion verification
Notes on syntax: DevTools flows are YAML-first and support request chaining and assertions. If your project uses a slightly different key naming (runner versions can evolve), keep the structure and adapt the keys to your schema. The important part is the dependency graph and how values are extracted and reused.
workspace_name: ProjectChainTest
env:
BASE_URL: '{{#env:BASE_URL}}'
USERNAME: '{{#env:USERNAME}}'
PASSWORD: '{{#env:PASSWORD}}'
RUN_ID: '{{#env:RUN_ID}}'
run:
- flow: ProjectChainTest
flows:
- name: ProjectChainTest
steps:
- request:
name: Health
method: GET
url: '{{BASE_URL}}/health'
headers:
Accept: application/json
- js:
name: ValidateHealth
code: |
export default function(ctx) {
if (ctx.Health?.response?.status !== 200) throw new Error("Health check failed");
}
depends_on: Health
- request:
name: Login
method: POST
url: '{{BASE_URL}}/auth/login'
headers:
Content-Type: application/json
Accept: application/json
body:
username: '{{USERNAME}}'
password: '{{PASSWORD}}'
depends_on: Health
- js:
name: ValidateLogin
code: |
export default function(ctx) {
const resp = ctx.Login?.response;
if (resp?.status !== 200) throw new Error("Login failed");
const token = resp?.body?.accessToken;
if (!token || typeof token !== "string") throw new Error("Missing accessToken");
if (token.length < 20) throw new Error("Token too short");
}
depends_on: Login
- request:
name: CreateProject
method: POST
url: '{{BASE_URL}}/v1/projects'
headers:
Content-Type: application/json
Accept: application/json
Authorization: 'Bearer {{Login.response.body.accessToken}}'
body:
name: 'chain-test-{{RUN_ID}}'
visibility: private
depends_on: Login
- js:
name: ValidateCreateProject
code: |
export default function(ctx) {
const resp = ctx.CreateProject?.response;
if (resp?.status !== 201) throw new Error("Create failed: " + resp?.status);
if (!resp?.body?.id) throw new Error("Missing project id");
if (resp?.body?.name !== "chain-test-" + ctx.env.RUN_ID) throw new Error("Name mismatch");
}
depends_on: CreateProject
- request:
name: GetProject
method: GET
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Accept: application/json
Authorization: 'Bearer {{Login.response.body.accessToken}}'
depends_on: CreateProject
- js:
name: ValidateGetProject
code: |
export default function(ctx) {
const resp = ctx.GetProject?.response;
if (resp?.status !== 200) throw new Error("Get failed");
if (resp?.body?.id !== ctx.CreateProject?.response?.body?.id) throw new Error("ID mismatch");
if (resp?.body?.visibility !== "private") throw new Error("Visibility mismatch");
}
depends_on: GetProject
- request:
name: UpdateProjectIfMatch
method: PATCH
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Content-Type: application/json
Accept: application/json
Authorization: 'Bearer {{Login.response.body.accessToken}}'
If-Match: '{{CreateProject.response.headers.etag}}'
body:
description: 'updated-by-chain-test-{{RUN_ID}}'
depends_on: GetProject
- js:
name: ValidateUpdate
code: |
export default function(ctx) {
const resp = ctx.UpdateProjectIfMatch?.response;
if (resp?.status !== 200) throw new Error("Update failed");
if (resp?.body?.description !== "updated-by-chain-test-" + ctx.env.RUN_ID) throw new Error("Description mismatch");
}
depends_on: UpdateProjectIfMatch
- request:
name: DeleteProject
method: DELETE
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Authorization: 'Bearer {{Login.response.body.accessToken}}'
depends_on: UpdateProjectIfMatch
- js:
name: ValidateDelete
code: |
export default function(ctx) {
const status = ctx.DeleteProject?.response?.status;
if (![200, 202, 204].includes(status)) throw new Error("Delete failed: " + status);
}
depends_on: DeleteProject
- request:
name: VerifyDeleted
method: GET
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Accept: application/json
Authorization: 'Bearer {{Login.response.body.accessToken}}'
depends_on: DeleteProject
- js:
name: ValidateVerifyDeleted
code: |
export default function(ctx) {
if (ctx.VerifyDeleted?.response?.status !== 404) throw new Error("Expected 404 after delete");
}
depends_on: VerifyDeleted
You now have an actual chain test. The next sections explain why each piece is there, how to tighten it for CI determinism, and how to handle the two hard problems: cleanup on failure and async consistency.
Step-by-step: chaining mechanics that matter
1) Start with a cheap “health” preflight
This step is not about correctness, it is about fast failure. If DNS is wrong, the environment is down, or you are pointed at the wrong base URL, you want to fail in 200ms, not after a login timeout.
Keep it minimal:
- no auth
- no dynamic inputs
- a single invariant (200 status)
2) Authentication: extract the token, assert its shape
Experienced teams often only assert status: 200 on login. That is too weak.
A good auth step asserts:
- the token field exists
- it is a string
- it is “plausibly real” (length threshold, or matches a JWT-ish pattern if applicable)
This catches a common regression where an auth service starts returning { token: null } with 200 due to a bad backend fallback.
Extraction is intentionally small:
- capture the
accessToken - do not store the full response as a variable blob
That keeps your test surface area tight and diffs smaller when auth payloads evolve.
3) Resource creation: capture stable identities (ID, Location, ETag)
For chain tests, the create step is where most suites become flaky, for three reasons:
- name collisions in shared environments
- hidden server-generated fields that change across runs
- eventual consistency (create returns 201, but read-after-write is not immediate)
The flow addresses collisions by including run_id in the name. For parallel CI, pick something unique per job.
It also captures ETag because optimistic locking is a real-world dependency. If your API does not use ETags, the same idea applies to version numbers.
4) Validation: assert invariants, not noise
After GET, the test asserts the identity and key fields.
Avoid brittle checks:
- timestamps equal to an exact value
- arrays with order that is not contractually guaranteed
- fields that depend on background jobs
If you need deeper assertion patterns (subset matching, tolerances, timestamp normalization), see JSON Assertion Patterns for API Tests and Deterministic API Assertions.
5) Cleanup: make it explicit, and verify it
Cleanup is not a “nice to have”. It is what keeps shared environments usable.
Two rules:
- Deletion should accept multiple success statuses because APIs differ (
200,202,204). - Verification should assert
404(or your contract’s equivalent) so you detect soft deletes or permission masking.
Variable extraction patterns you will need beyond the happy path
The tutorial flow extracted from:
- JSON body (
$.accessToken,$.id) - header (
ETag)
In real suites, you will also extract:
Locationheader for newly created resources- cookies (session-based auth)
- pagination cursors
Here are a few practical patterns in YAML form.
Extract from Location header (create returns URL)
Some APIs return an ID only in Location.
- request:
name: CreateWidget
method: POST
url: '{{BASE_URL}}/v1/widgets'
headers:
Content-Type: application/json
Authorization: 'Bearer {{Login.response.body.accessToken}}'
body:
name: 'widget-{{RUN_ID}}'
depends_on: Login
- js:
name: ValidateCreateWidget
code: |
export default function(ctx) {
const resp = ctx.CreateWidget?.response;
if (resp?.status !== 201) throw new Error("Create failed");
if (!resp?.headers?.location) throw new Error("Missing Location header");
}
depends_on: CreateWidget
Then you can GET {{CreateWidget.response.headers.location}} directly without reconstructing paths.
Extract cookie-based sessions (when Authorization is not used)
If your API uses a session cookie, the chain dependency is the cookie jar. Tools differ on how they persist cookies between steps.
A deterministic approach is to capture the specific cookie you need and send it explicitly:
- request:
name: LoginCookie
method: POST
url: '{{BASE_URL}}/session'
headers:
Content-Type: application/json
body:
username: '{{USERNAME}}'
password: '{{PASSWORD}}'
- js:
name: ValidateLoginCookie
code: |
export default function(ctx) {
const resp = ctx.LoginCookie?.response;
if (resp?.status !== 200) throw new Error("Session login failed");
const cookie = resp?.headers?.["set-cookie"];
if (!cookie || !cookie.includes("session=")) throw new Error("Missing session cookie");
}
depends_on: LoginCookie
Then send it:
headers:
Cookie: '{{LoginCookie.response.headers.set-cookie}}'
Whether you should do this depends on your runner’s cookie handling. The point is: make the dependency visible.
Extract pagination cursors for multi-page validation
Cursor pagination is a classic chain test because you need the output of page 1 to fetch page 2.
- request:
name: ListPage1
method: GET
url: '{{BASE_URL}}/v1/projects?limit=50'
headers:
Authorization: 'Bearer {{Login.response.body.accessToken}}'
depends_on: Login
- js:
name: ValidateListPage1
code: |
export default function(ctx) {
const resp = ctx.ListPage1?.response;
if (resp?.status !== 200) throw new Error("List failed");
if (!resp?.body?.nextCursor) throw new Error("Missing nextCursor");
}
depends_on: ListPage1
- request:
name: ListPage2
method: GET
url: '{{BASE_URL}}/v1/projects?limit=50&cursor={{ListPage1.response.body.nextCursor}}'
headers:
Authorization: 'Bearer {{Login.response.body.accessToken}}'
depends_on: ListPage1
- js:
name: ValidateListPage2
code: |
export default function(ctx) {
if (ctx.ListPage2?.response?.status !== 200) throw new Error("Page 2 failed");
}
depends_on: ListPage2
In higher-signal suites, you also assert stable ordering constraints (if your contract defines them) and that items are not duplicated across pages.
Assertions between steps: treat each edge as a contract
A chain test is a graph. Every edge is a contract:
- login produces token
- create consumes token, produces ID
- get consumes ID
- delete consumes ID
A common anti-pattern is a single “final assertion” at the end. That makes failures expensive to debug.
Instead:
- assert existence/type immediately after extraction
- assert identity fields (
id) on reads - assert server headers that matter (
content-type, cache rules, rate limit headers)
If you need a catalog of assertion types, API Assertions in YAML is a good reference.
Error handling patterns that keep CI and environments sane
Chained tests fail. The question is whether they fail in a way that:
- leaves your environment clean
- produces actionable output
- avoids cascading failures that waste CI minutes
Here are pragmatic patterns that do not depend on any “magic” runner feature.
Pattern 1: Idempotent cleanup (delete can be retried safely)
If cleanup can run twice without causing a failure, you can safely run it in more situations.
For delete requests:
- accept
404as “already deleted” - accept
409only if you know your API returns it during async deletes (rare)
Example:
- request:
name: CleanupDeleteProject
method: DELETE
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Authorization: 'Bearer {{Login.response.body.accessToken}}'
depends_on: CreateProject
- js:
name: ValidateCleanupDelete
code: |
export default function(ctx) {
const status = ctx.CleanupDeleteProject?.response?.status;
if (![200, 202, 204, 404].includes(status)) throw new Error("Cleanup failed: " + status);
}
depends_on: CleanupDeleteProject
This prevents secondary failures when you rerun a job or when teardown runs after a partial create.
Pattern 2: Make teardown a separate flow, run it even when tests fail
Many CI systems stop executing steps after a failing command unless you tell them otherwise. A robust approach is:
- the main flow writes out the created IDs as outputs (file, env, or runner output)
- a teardown flow consumes those IDs
- CI runs teardown with an “always run” condition
You can implement this in GitHub Actions with an if: always() step. DevTools already has a complete guide for CI wiring, see API regression testing in GitHub Actions.
A teardown flow can be a tiny YAML file:
workspace_name: TeardownProject
env:
BASE_URL: '{{#env:BASE_URL}}'
ACCESS_TOKEN: '{{#env:ACCESS_TOKEN}}'
PROJECT_ID: '{{#env:PROJECT_ID}}'
run:
- flow: Teardown
flows:
- name: Teardown
steps:
- request:
name: Delete
method: DELETE
url: '{{BASE_URL}}/v1/projects/{{PROJECT_ID}}'
headers:
Authorization: 'Bearer {{ACCESS_TOKEN}}'
- js:
name: ValidateDelete
code: |
export default function(ctx) {
const status = ctx.Delete?.response?.status;
if (![200, 202, 204, 404].includes(status)) throw new Error("Teardown failed: " + status);
}
depends_on: Delete
This pattern scales when your chain creates multiple resources (projects, users, billing objects) and you want cleanup to be centrally managed.
Pattern 3: Localize failures with “checkpoint” assertions
If your create step returns 201 but you forgot a required field, the read step might still return a representation that looks “fine”. Later operations fail in confusing ways.
Add checkpoint assertions right after create:
- ID exists and is not empty
- fields you control echo back correctly
- a header you depend on (ETag, Location) exists
This makes failures point to the exact step that violated expectations.
Pattern 4: Eventual consistency, poll with a bounded budget
If POST is async (write accepted, read side lags), a naive GET immediately after create will be flaky.
You need a polling loop with:
- a maximum number of attempts
- fixed or exponential backoff
- a clear failure message
If your DevTools flow runner supports loops/conditions, implement polling inside the flow. If not, implement polling at the CI wrapper level.
A YAML sketch of the polling intent (adapt to your loop syntax):
- for:
name: WaitUntilReadable
range: 10
steps:
- request:
name: GetProjectEventual
method: GET
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Authorization: 'Bearer {{Login.response.body.accessToken}}'
- js:
name: CheckReadable
code: |
export default function(ctx) {
if (ctx.GetProjectEventual?.response?.status === 200) return { done: true };
return { done: false };
}
depends_on: GetProjectEventual
depends_on: CreateProject
The key is the bounded budget. A test that “eventually passes” after 90 seconds is not a good regression gate.
Pattern 5: Treat auth failures as a distinct class
Auth failure will cascade into 401s everywhere. Make that obvious:
- assert token shape
- optionally assert claims if you are using JWT and your runner can decode it
- separate “auth contract” flows from “business logic” flows
That way a broken auth deployment does not look like “projects API regressed”.
Making chain tests reviewable in pull requests
Chained YAML tests pay off when they are easy to review. Two practical conventions:
- Keep step IDs stable. Renaming step IDs creates noisy diffs and breaks references.
- Keep extraction next to the request that produces it. Avoid “global variable soup”.
If your suite is already large, enforce formatting rules (sorted headers, stable key ordering) so that “change a header” does not rewrite the file. The DevTools conventions post mentioned earlier is a good baseline.
Postman/Newman vs Bruno vs YAML-first chaining (what actually changes)
Chaining is possible everywhere. The difference is how it behaves when you put it in Git and CI.
Postman collections (and Newman in CI)
Postman typically chains via:
- collection variables / environment variables
- pre-request scripts and test scripts (JavaScript)
In CI, Newman executes the collection export (JSON). Common friction points:
- diffs are noisy because exports reorder keys or include UI metadata
- scripts can become a shared global state across requests
- reviewing “what changed” in a pull request is slower than reviewing YAML
If you are currently in Newman, see Newman alternative for CI: DevTools CLI.
Bruno
Bruno improves the “local files in Git” story compared to Postman, but it is still a tool-specific format (.bru) rather than native YAML. If you care about portability across teams and minimal schema friction, plain YAML tends to be easier to integrate with existing toolchains (linters, renderers, internal generators).
YAML-first (DevTools)
The practical differences for chaining:
- the chain is readable without opening a GUI
- step outputs can be referenced explicitly
- the flow is diffable and code-reviewable
- CI runners can shard flows by file path and run them in parallel
For CI-native structure patterns (smoke vs regression, sharding, reporting), see API Testing in CI/CD: From Manual Clicks to Automated Pipelines.
Advanced scenario: add a negative check without breaking determinism
A good chain test often includes one or two negative assertions that verify access control. Keep them deterministic:
- do not rely on timing
- do not rely on random data
- keep the failure localized
Example: after creation, try reading the project with a token that lacks scope.
You can do this by logging in as a restricted user (separate credentials) and asserting 403.
- request:
name: LoginRestricted
method: POST
url: '{{BASE_URL}}/auth/login'
headers:
Content-Type: application/json
body:
username: '{{RESTRICTED_USERNAME}}'
password: '{{RESTRICTED_PASSWORD}}'
depends_on: Health
- js:
name: ValidateLoginRestricted
code: |
export default function(ctx) {
if (ctx.LoginRestricted?.response?.status !== 200) throw new Error("Restricted login failed");
}
depends_on: LoginRestricted
- request:
name: GetProjectForbidden
method: GET
url: '{{BASE_URL}}/v1/projects/{{CreateProject.response.body.id}}'
headers:
Authorization: 'Bearer {{LoginRestricted.response.body.accessToken}}'
depends_on: CreateProject
- js:
name: ValidateForbidden
code: |
export default function(ctx) {
if (ctx.GetProjectForbidden?.response?.status !== 403) throw new Error("Expected 403, got: " + ctx.GetProjectForbidden?.response?.status);
}
depends_on: GetProjectForbidden
This catches the “created resources are accidentally world-readable” class of regression, without introducing flaky dependencies.
When to use a JS extraction/validation node (and when not to)
Many API checks are expressible as JSONPath assertions. Use them first.
Use a JS node when you need:
- derived values (hashing, canonicalization)
- multi-field logic (if A then B)
- more precise failure messages than a single JSONPath can provide
If you do use JS, keep it small and deterministic. Avoid time-based branching.
A JS node might validate that an array is sorted by createdAt and that items have unique IDs (pseudo-example):
- js:
name: ValidateSortAndUniqueness
code: |
export default function(ctx) {
const items = ctx.ListPage1?.response?.body?.items || [];
const ids = new Set();
for (const it of items) {
if (!it.id) throw new Error("missing id");
if (ids.has(it.id)) throw new Error("duplicate id: " + it.id);
ids.add(it.id);
}
return { uniqueCount: ids.size };
}
depends_on: ListPage1
The key is that JS is the exception, not the default glue.
CI integration: what to pin and what to store
Chain tests are only useful if CI results are auditable and repeatable.
Two practical recommendations:
- Pin runner and tooling versions so your suite does not drift (see Pinning GitHub Actions + Tool Versions).
- Store artifacts that explain failures (JUnit XML, logs) without dumping secrets (see Auditable API Test Runs).
If you already have GitHub Actions, the simplest workflow is:
- run smoke chain tests on every PR
- run broader regression flows post-merge or nightly
- always upload JUnit/log artifacts
DevTools has a dedicated guide you can copy-paste from: API regression testing in GitHub Actions.
Practical checklist: what makes a chain test “CI-grade”
Before you call a chain flow production-ready, verify:
- Inputs are parameterized (base URL, credentials, run ID).
- Every step has at least one meaningful assertion.
- IDs and tokens are extracted explicitly, not copied into static fixtures.
- Created resources include a unique suffix so parallelism is safe.
- Cleanup exists, is idempotent, and deletion is verified.
- Eventual consistency is handled with bounded polling (or you have a synchronous endpoint).
- The YAML stays readable in diffs (stable step IDs, stable key ordering).
If you are starting from browser traffic, generate the chain instead of hand-writing it
If your workflows are already exercised in a browser, a fast path is:
- capture a bounded HAR that starts with auth
- redact secrets
- convert HAR to YAML
- normalize and chain the generated steps
That pipeline is covered in Chrome DevTools Network to YAML Flow and HAR → YAML API Test Flow.
The important detail for chain testing is what happens after conversion: you remove browser-only noise and make dependencies explicit (token, IDs, CSRF), then add deterministic assertions.
Summary
API chain testing is the difference between “each endpoint returns 200” and “the system works as a workflow”. A CI-grade chain flow:
- turns auth, resource IDs, and concurrency tokens into explicit extracted variables
- asserts invariants after each step
- cleans up reliably (even after failures)
- stays readable and reviewable in Git
If your current approach depends on UI-edited collections or custom formats, moving the chain into native YAML is often the simplest way to make it deterministic, portable, and CI-friendly.